4. 요약 통계량 (Summary Statistics)
- 데이터의 전체적인 특성을 한눈에 파악하기 위해 수치로 요약한 값들이다.
- 크게 중심 위치를 나타내는 값과 퍼진 정도를 나타내는 값으로 나뉜다.
(1). 기초 지표
1. 범위 (Range) :
- 최댓값과 최솟값의 차이 (Max - Min)
- 데이터가 전체적인 어느 정도 구간에 분포하는지 보여줌
2. 최빈값 (Mode) :
- 가장 자주 등장하는 값
- 명목형 자료(성별, 혈액형 등)에서 사용할 수 있는 유일한 대푯값
(2). 중심의 측도 : 평균과 중앙값
데이터가 어디에 모여 있는지를 나타낸다.
1. 산술 평균 (Arithmetic Mean) :
- 모든 값을 더해 개수로 나눈 일반적인 평균
- 비가중 평균 : 모든 데이터에 동일한 중요도(가중치 1)를 부여하여 계산한 산술 평균
2. 기하 평균 (Geometric Mean) :
- 값을 모두 곱한 뒤 n제곱근을 취함
- 성장률, 수익률처럼 비율로 변화하는 데이터에 사용
3. 조화 평균 (Harmonic Mean) :
- 역수의 산술 평균을 구한 뒤 다시 역수를 취함
- 평균 속력이나 일정 금액으로 물건을 살 때의 평균 가격 계산에 적합
4. 중앙값 (Median) :
- 데이터를 크기순으로 세웠을 떄 정중앙에 위치한 값
- 극단적인 값(이상치)의 영향을 덜 받는다는 장점이 있음
5. 매튜 상관계수 (MCC) :
- 주로 분류 모델 성능을 평가할 때 쓰임
- 불균형한 데이터넷에서도 모델의 예측 능력을 정확히 요약해주는 지표
(3). 변동의 측도 : 데이터가 얼마나 퍼져 있는가?
변동의 측도는 데이터가 평균을 기준으로 얼마나 흩어져 있는지(산포도)를 나타내는 지표
평균이 데이터의 '중심'을 나타낸다면 변동의 측도는 데이터의 안정성, 일관성을 보여줌
1. 편차(Deviation) :
- 편차란 각 데이터 값에 평균을 뺀 값
- 각 값이 평균에서 얼마나 떨어져 있는지를 나타냄

문제점 :
- 편차에는 양수와 음수가 섞여 있음
- 따라서 편차의 합은 항상 0
- 그대로는 데이터의 퍼짐 정도를 나타낼 수 없음
⇒ 그래서 편차를 가공한 지표가 필요함
2. 분산 (Variance) : 퍼짐 정도를 수치화
- 분산은 편차를 제곱한 뒤 평균을 낸 값
- 제곱을 사용함으로써
→ 음수 문제를 제거하고, 평균에서 멀리 떨어진 값에 더 큰 영향을 주게 됨
⇒ 분산은 데이터의 퍼짐 정도를 수학적으로 잘 표현함
⇒ 하지만 단위가 제곱(cm^2, kg^2 등) 이라는 단점이 있음

3. 평균 편차 (Mean Deviation) : 직관적이지만 덜 쓰임
- 평균 편차는 편차에 절댓값을 씌워 평균을 낸값
- 제곱 대신 "거리" 개념을 사용해 직관적
하지만..
- 미분이 어려워 이론적 분석에 불리함
- 통계 이론과 확률 분포에서 잘 쓰이지 않음
⇒ 그래서 실무, 이론 모두에서 분산과 표준편차가 더 널리 쓰임

4. 표본분산의 두 종류
표본으로 분산을 계산할 떄는 나누는 값에 따라 의미가 달라진다.
(1). 편향 표본분산
- 분모를 n으로 나눈 분산
- 모집단 분산보다 작게 추정되는 경향(편향)이 있음
(2). 비편향 표본 분산
- 이를 보정하기 위해 n - 1로 나눈 분산
- 모집단의 분산의 기대값과 일치
- 일반적으로 "표본분산"이라 하면 이것을 의미함

5. 표준편차(Standart Deviation) : 실무에서 가장 많이 쓰는 지표
- 표준편차는 분산에 제곱근을 취한 값이다.
- 단위를 원래 데이터와 맞춰 준다. (cm, kg, 시간 등)
그래서
- 분산 : 수학적, 이론적 분석에 유리
- 표준편차 : 해석과 비교에 가장 적합

정리하면
- 편차 : 평균에서 얼마나 떨어져있는지
- 분산 : 퍼짐 정도를 수치화
- 표본분산 : n - 1로 나눈 비편향 분산을 사용
- 표준편차 : 실제 해석과 실무의 핵심 지표
5. 분위수와 상자 그림
(1). 분위수(Quantile)란?
데이터를 크기순으로 정렬한 뒤, 같은 비율로 잘라서 위치를 나타내는 값
- "이 값보다 작은 데이터가 전체의 몇 %인가?"를 말해줌
- 데이터의 위치 정보를 알려주는 지표
예를 들면 :
- 25% 분위수 전체 데이터 중 하위 25%지점
- 50% 분위수 전체 데이터의 정중앙
(2). 이분위수(Median)
- 데이터를 2등분하는 값이다.
- 데이터를 정렬했을 떄 가운데 값
- 위쪽 50%, 아래쪽 50%로 나눔
- 통계에서 흔히 말하는 중앙값(Median)
⇒ 극단적인 값(이상치)에 영향을 덜 받음
(3). 50 백분위수 = 정중앙값
- 백분위수(Percentile)는 0 ~ 100 기준으로 위치를 나타낸 것
- 50 백분위수 = 50% 지점
- 즉, 중앙값 = 이분위수 = 50 백분위수
⇒ 이름만 다르고 의미는 동일
(4). 사분위수(Quartile)
- 데이터를 4등분한 값이다.
- Q1 (1사분위) : 25% 지점
- Q2 (2사분위) : 50% 지점 → 중앙값
- Q3 (3사분위) : 75% 지점
⇒ 데이터가 어디에 몰려 있는지 보기 좋음

근데 왜 Q4 (4사분위)는 없냐?
- 사분위수는 데이터를 4등분하기 위해 필요한 '경계값'이다.
- 4등분을 하려면 경계선을 3개만 있으면 충분하다. → 사진처럼
예를 들면 :
- 초콜릿을 4조각으로 나누려면
- 칼질은 3번만 하면 됨
즉,
[최솟값] - Q1 - Q2 -Q3 - [최댓값]
- 최솟값 ~ Q1
- Q1 ~ Q2
- Q2 ~ Q3
- Q3 ~ 최댓값
이렇게 구간은 4개로 나눠진 것임
(5). 상자 그림(Box Plot)란?
사분위수 + 데이터 퍼짐 + 이상치를 한 번에 보여주는 그림
구성 요소 :
- 상자(Box) : Q1 ~ Q3
- 가운데 선 : 중앙값(Q2)
- 수염(Whisker) : 정상 범위의 끝
- 점(Fliers) : 이상치
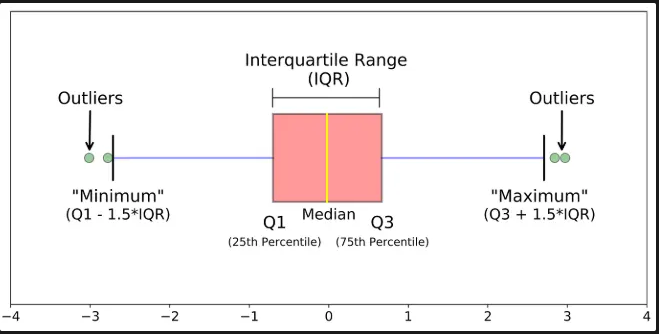
이 그림은 데이터의 분포와 이상치를 한 번에 보여주는 그래프이다.
- 상자(Nox) : Q1 ~ Q3
- 데이터의 중앙 50% 범위(IQR)
- 가운데 선 : 중앙값(Q2)
- 데이터의 중심
- 수염(Whisker)
- 정상 범위 끝 (Q1 -1.5 x IQR ~ Q3 + 1.5 x IQR)
- 점(Fliers)
- 수염 밖에 있는 값 → 이상치
상자 그림은 데이터가 어디에 몰려 있고, 얼마나 퍼져 있으며, 이상치가 있는지를 한눈에 보여줌
1. 수염, 플라이어, 잠재적 이상치
수염 (Whisker)
- Q1, Q3에서 1.5 x IQR 이내의 범위
- “정상 데이터의 끝”을 의미
플라이어 (flyer)
- 수염 밖에 있는 점
- 이상치(outlier)로 표시됨
잠재적 이상치
- 반드시 틀린 값은 아님
- 비정상적으로 크거나 작은 값
- 분석 목적에 따라서 제거할 수도 있고, 중요한 신호일 수도 있음
? IQR
IQR = Q3 - Q1
- Q1 : 25% 지점
- Q3 : 75% 지점
즉, 가운데 절반(50%) 데이터 범위
IQR이 왜 필요함?
- 평균이나 전체 범위(Max-Min)는
- 극단적인 값(이상치)에 쉽게 흔들림
IQR은 :
- 가장 작은 값이 아니고
- 가장 큰 값도 아니다
- 중앙에 있는 데이터만 사용한다
⇒ 그래서 이상치에 강한 지표이다.
상자그림(Boxplot)에서 IQR?
- 상자의 길이 = IQR
- 상자 안 = 전체 데이터의 중앙 50%
- 상자가 길수록 → 변동성 큼
- 상자가 짧을수록 → 안정적
IQR과 이상치 판별
IQR은 이상치를 찾는 기준으로도 씀
- 하한 = Q1 - 1.5 x IQR
- 상한 = Q2 + 1.5 x IQR
- 이 범위를 벗어나면 잠재적 → 이상치
정리하면
- IQR = Q3 - Q1
- 데이터 중앙 50%의 퍼짐 정도
- 이상치에 강한 지표
- 상자그림의 상자 크기 그 자체
(6). 결측자료 (Missing Data)
값이 비어 있거나(None, NaN) 없는 데이터
문제점 :
- 평균, 분산 계산 왜곡
- 그래프에서 구멍 발생
처리 방법 :
- 제거
- 평균/중앙값으로 대체
- 보간(interpolation)

이 그림은 데이터 결측값(Missing Data)이 있을 떄 생기는 문제와 이를 시각적으로 확인하는 방법을 보여줌
그림을 해석하면
- 표 : 어떤 데이터가 결측인지 표시
- 왼쪽 덴드로그램 :
- 결측값이 비슷한 패턴으로 발생하는 변수들을 묶어줌
- 오른쪽 히트맵 :
- 결측이 함께 발생하는 변수 간의 관계를 시각화
? 보간(interpolation)
비어 있는 값 사이를 주변 값으로 추정해 채우는 것
왜?
- 데이터 중간에 값이 빠졌을 때
- 그냥 삭제하기엔 정보가 아까울 때
- 연속적인 데이터(시간, 위치 등)에서 특히 유용
가장 흔한 방식은 선형 보간이다.
- 앞, 뒤 값을 직선으로 연결
- 중간 값을 그 선 위에서 추정
근데
- 급격한 변화가 있는 데이터에는 부정확할 수 있음
- 결측이 많으면 신뢰도가 낮아짐
정리하면
1. 분위수(Quantile)
- 데이터를 정렬한 뒤 같은 비율로 나눈 위치값
- "이 값보다 작은 데이터가 전체의 몇 %인가?"를 의미
- 데이터의 상대적 위치를 알려줌
2. 이분위수(Median)
- 데이터를 2등분한 값
- 정렬했을 때 가운데 값
- 중앙값 = 이상치에 강함
3. 백분위(Percentile)
- 데이터를 0~100 기준으로 나눈 위치
- 50 백분위수 = 중앙값 = 이분위수
- 이름만 다르고 의미는 동일
4. 사분위수(Quartile)
- 데이터를 4등분하기 위한 경계값
- Q1 = 25%, Q2 = 50%(중앙값), Q3 = 75%
- 데이터가 어디에 몰려 있는지 파악하기 좋음
5. 상자그림(Box Plot)
- 사분위수 + 퍼짐 + 이상치를 한 번에 표현
구성 요소 :
- 상자 : Q1 ~ Q3
- 중앙선 : Q2(중앙값)
- 수염 : 정상 범위
- 점 : 이상치
6. 수염, 플라이어, 이상치
- 수염(Whisker) : Q1, Q3 기준 1.5 x IQR 이내
- 플라이어(Flyer) : 수염 밖 점 → 이상치
- 잠재적 이상치 : 제거 대상일 수도, 중요한 신호일 수도 있음
6. 상관관계 (Correlation)
두 변수가 함께 어떻게 변하는지를 나타낸다.
- 한 변수가 커질 떄 다른 변수도 커지면 → 양의 상관
- 한 변수가 커질 때 다른 변수는 작아지면 → 음의 상관
- 아무 패턴 없으면 상관 없음
근데
상관관계 ≠ 인과관계
상관관계는 두 변수가 함께 변하는 경향이 있다는 사실만 말해줌
⇒ 한 변수가 다른 변수를 "원인"으로 만든다는 뜻은 아님
1. 우연히 같이 변할 수도 있다
- 두 변수 모두 시간, 계절, 사회적 분위기 같은
- 제 3의 요인에 영향을 받을 수 있음
예 :
- 아이스크림 판매량 ↑
- 익사 사고 ↑
⇒ 이것은 여름이라는 공통 원인 때문이지 아이스크림이 익사를 일으키는 건 아님
2. 방향을 알 수 없다
상관관계만으로는
- A → B인지
- B → A 인지
- 아니면 서로 영향이 없는지
를 구분할 수 없다.
예 :
- 커피를 많이 마셔서 → 집중력이 높아질 수도 있고
- 집중해야 할 일이 많아서 → 커피를 더 마실 수도 있음
3. 완전히 말이 안 되는 상관도 존재한다
- 실제로는 높은 상관계수를 가지지만
- 인과관계가 전혀 없는 경우도 많다.
예 :
- 해적 수 ↓
- 지구 평균 기온 ↑
- 숫자상 상관은 있어도
- 원인, 결과 관계는 없다.
상관관계는 "같이 변한다"는 관찰 결과일 뿐이며,
왜 변하는지, 누가 원인인지는 설명하지 못한다.
아래는 상관관계의 예시 그림이다.

이 그림은 두 변수 X와 Y가 함께 어떻게 변하는지를 보여준다.
왼쪽 : 양의 상관관계 (Positive Correlation)
- X가 커질수록 Y도 커짐
- 두 변수가 같은 방향으로 변화
가운데 : 음의 상관관계 (Negative Correlation)
- X가 커질수록 Y는 작아짐
- 두 변수가 반대 방향으로 변화
오른쪽 : 상관 없음 (No Correlation)
- X와 Y 사이에 뚜렷한 패턴이 없다
- 함께 변하는 관계가 보이지 않음
⇒ 상관관계는 함께 변하는 정도일 뿐, 원인과 결과를 뜻하지 않는다.
(1). 선형(linear)란?
- 점들이 직선에 가깝게 모여 있는 것
- 직선으로 설명 가능하면 → 선형 관계
(2). 피어슨 상관계수 (Pearson Correlation)
피어슨은 직선 관계만 본다.
- 선형 관계일 때
- 연속형 수치 데이터
이럴 때 사용한다.
⇒ 그래서 이상치에 민감하다.
수식 :

- 분자 : 같이 움직인 정도
- 분모 : 각 변수의 흩어진 정도로 정규화
- 결과 : -1 ~ 1
| 값 | 의미 |
| 1 | 완벽한 양의 선형 |
| 0 | 선형 관계 없음 |
| -1 | 완벽한 음의 선형 |
아래 그림은 피어슨 상관계수 r 값이 데이터 모양에 따라 어떻게 달라지는지를 보여주는 그림이다.

하나씩 보면
- a = -1 : 완벽한 음의 선형 관계 (x가 커질수록 y는 감소)
- r = 0.94 : 거의 직선에 가까운 강한 음의 선형 관계
- r = +0.08 : 점들이 흩어져 있음 ⇒ 선형 관계가 거의 없음
- r = +1 : 완벽한 양의 선형 관계 (x가 커질수록 y도 증가)
- r = 0.86 : 꽤 뚜렷한 양의 선형 관계
- r = 0 : 선형 상관 없음 (하지만 곡선 관계는 존재할 수 있다.)
r = 0은 아무 관계 없음이 아니라 직선 관계가 '없음'이라는 것이다.
정리하면
피어슨 상관계수 r은 얼마나 직선에 가까운가를 수치로 나타낸 값이다.
(3). 기대값 (Expecatation)
기대값 = 평균의 이론적 표현

이 수식은
- 각 값에 그 값이 발생할 확률을 곱한 뒤, 이를 모두 더한 값이다.
- 확률을 고려한 평균임
기호 :
- x : 나올 수 있는 값
- P(x) : 그 값이 나올 확률
- ∑ : 가능한 모든 경우를 다 더함
- 자주 나오는 값 → 평균에 큰 영향
- 거의 안 나오는 값 → 영향이 작음
⇒ 그냥 평균이 아니라 "확률로 가중치를 준 평균"
예를 들면 :

주사위 눈의 기대값이 위와 같다고 해보자
수식을 계산하면
- 실제로는 3.5는 나오지 않지만
- 장기적으로 평균은 3.5이다.
즉,
- 기대값은 장기적으로 얻을 평균 결과를 수식으로 표현한 것이다.
⇒ 확률을 고려한 평균값
- 상관계수, 분산, *검정 통계량 전부 기대값 기반
- 통계 이론의 뼈대
? 검정
검정 = 가설 검정 (Hypothesis Testing)
1. 가설 검증의 핵심 아이디어 (기대값 관점)
- 이 통계량의 기대값이 0 또는 특정 값일 텐데,
- 실제 데이터에서 나온 값이 너무 멀지 않은가?
즉,
- 이론적으로 기대되는 값(기대값)과
- 실제로 관측된 값
을 비교하는 절차이다.
2. 검정 통계량 (TestStatistic)
- (관측값 - 기대값) / 변동성
이 형태는 거의 모든 검정에서 반복됨
3. t-검정과 기대값
- 평균을 비교하고 싶다
- "이 표본평균이 정말 다른가?"
*영가설

⇒ 기대값 : 표본평균의 기대값은 u0
? 영가설
통계적 가설 검정에서 차이, 관계, 효과가 없다고 가정하는 기본 가설
t-통계량

- 분자 : 관측된 평균 - 기대되는 평균
- 분모 : 표본평균의 표준오차
- 결과 : 기대값에서 몇 표준오차만큼 떨어져있는가?
⇒ 기대값에서 너무 멀면 → 영가설 기각
왜?
t-검정 = 표본평균이 기대값에서 우연이라고 보기엔 너무 멀다를 판단
4. 상관계수 검정도 기대값 기반

⇒ 기대값 : 상관계수의 기대값은 0 (관계 없음)
실제로는
- 계산한 상관계수 r이
- 0에서 너무 멀면 → 관계 있음
이것도 구조는 동일함
관측값 - 기대값
----------------------
변동성
5. 맨-휘트니 U 검정과 기대값
- t-검정은 정규분포 가정 필요
- 그 가정이 깨질 때 쓰는 비모수 검정
맨-휘트니 U 검정은 평균을 직접 비교하지 않음
대신에
- 두 집단이 같은 분포에서 나왔으면 순위가 비슷해야 한다
를 봄
영가설

⇒ 이때 *U 통계량의 기대값이 존재함
? U통계량
- 모든 데이터를 합쳐서 순위를 매김
- 한 집단의 순위 합을 계산
- 그 값이 기대되는 순위 합에서 얼마나 벗어났는지 확인
구조는 동일함
- 관측된 순위 합 vs 기대되는 순위 합
6. t-검정 vs 맨-휘트니 U 비교
| 구분 | t-검정 | 맨-휘트니 U |
| 비교 대상 | 평균 | 순위 |
| 기대값 | 평균 | 순위의 기대값 |
| 분포 가정 | 정규 | 없음 |
| 검정 본질 | 평균이 기대값에서 얼마나 벗어났나 | 순위가 기대값에서 얼마나 벗어났나 |
7. 기대값이 통계의 뼈대?
- 분산 = 기대값 기반
- 표준오차 = 기대값 기반
- 검정 통계량 = (관측 - 기대) / 변동성
- p-value = 기대값 기준 확률
즉,
- 통계적 검정 = 기대값에서 벗어난 정도를 확률로 해석하는 과정
(4). 스피어먼 상관계수 (Spearman)
- 순위 관계만 중요할 때
- 선형이 아닐 때
- 이상치에 강함
이럴 때 사용함
핵심은
- 값을 순위(rank)로 바꿈
- 그 순위들로 피어슨 상관 계산

- n : 데이터 개수
- di : 각 데이터의 순위 차이
(x의 순위 - y의 순위)
- ∑di^2 : 순위 차이를 제곱해서 전부 더한 값
| p 값 | 의미 |
| 1 | 순위 완전히 같음 |
| 0 | 순위 관계 없음 |
| -1 | 순위 완전히 반대 |

이 그림을 설명하면
왼쪽 & 가운데 : 단조 관계 (Monotonic)
- x가 증가하면 y가 계속 감소 (왼쪽 그림)
- x가 증가하면 y가 계속 증가 (가운데 그림)
- 직선일 필요는 없음
⇒ 스피어먼 상관계수로 잘 잘힘
오른쪽 : 비단조 관계 (Non-Monotonic)
x가 증가했도 y가
- 증가했다가
- 감소하는 등
- 방향이 바뀜
⇒ 피어슨, 스피어먼 모두 상관을 잘 못 잡음
단조 관계는 방향이 한 번도 바뀌지 않고, 비단조 관계는 중간에 방향이 바뀐다.
(5). 가설 검정 (Hypothesis Testing)
우연인지, 의미 있는 차이인지 판단하는 절차
가설
- 영가설(H0) : 차이 / 관계 없음
- 대립가설(H1) : 차이 / 관계 있음
양측 : 검정
- 크든 작든 차이가 있으면 의미 있음
(6). 모수적 vs 비모수적
| 구분 | 모수적 | 비모수적 |
| 가정 | 정규분포, 평균, 분산 | 분포 가정 없음 |
| 예시 | t-검정 | 맨-휘트니, 윌콕슨 |
| 장점 | 강력 | 안전 |
(7). 독립 동일 분포 (i.i.d.)
- 독립 : 서로 영향 없음
- 동일 분포 : 같은 분포에서 나옴
⇒ 거의 모든 통계 검정의 기본 가정
(8). 신뢰구간 & 임계값
신뢰구간 :
- "진짜 값이 이 안에 있을 확률 95%"
임계값
- 이 선을 넘으면 → 영가설 기각

이 그림을 설명하자면
시대가 바뀌면서 자주 사용하는 영어 표현을 그래프로 표현한 것이다.
- 가로축 : 시대 (1920s → 1960s → 2000s)
- 세로축(p) : 각 표현이 사용될 확률(비율)
이게 뭘 나타내냐?
- cogitate : 가장 많이 쓰였음 → 시간이 지날수록 안씀
- intend : 1960년대에 잠깐 증가했다가 다시 감소
- quotative : 시간이 지날수록 꾸준히 증가
- interpretative : 전체적으로 낮지만 조금씩 증가
막대(오차막대)의 의미
- 값의 불확실성(신뢰 범위) 표시
(9). 효과 크기 (Effect Size)
통계적으로가 아니라, 실제로 얼마나 큰 차인인가
코헨의 d
- 두 집단 평균 차이가, 데이터의 흔들림에 비해 얼마나 큰가? 를 나타내는 값

분자 :
- 두 집단의 평균 차이
- 실제로 얼마나 차이 나느냐?
⇒ 눈에 보이는 차이
분모 :
- 두 집단의 데이터의 표준편차(흔들림 정도)
- 데이터가 얼마나 퍼져 있는지
⇒ 자연스러운 변동
- 평균 차이가 데이터 흔들림보다 크면 → d가 크다
- 평균 차이가 흔들림에 묻히면 → d가 작다
즉,
같은 5점 차이라도
- 점수들이 거의 비슷하면 → 큰 차이
- 점수들이 뜰쭉날쭉하면 → 작은 차이
| d | 해석 |
| 0.2 | 작음 |
| 0.5 | 중간 |
| 0.8 | 큼 |
출처 :
https://89douner.tistory.com/188
[통계학]2-1.표본 통계량(표본평균, 표본분산, 자유도, 표본분포)
표안녕하세요. 지난 글에서 통계학에 대한 제 개인적인 정의를 내린바 있습니다. "나의 주장(가설)을 보편 타당하게 증명하는 과정" 가설설정(Statistical hypothesis setting) = 내가 주장하려고 하는 바
89douner.tistory.com
https://lucete1504.tistory.com/12
통계_범주형 자료, 양적 자료, 명목형 , 순서형, 연속형, 이산형, 구간형, 비율형 자료
안녕하세요! 눈꽃입니다~ 이번 시간에는 통계의 원자재라고 볼 수 있는 '자료'에 대해서 알아봅시다! 첫 포스팅에서 자료는 관찰이나 실험 등을 통해 구할 수 있고, 그렇게 얻어진 원시자료는 양
lucete1504.tistory.com