https://link.springer.com/article/10.1007/s10586-025-05281-5
리뷰 논문이어서 의료 분야에서 XAI가 어떻게 사용되는지만 정리하려고 했는데, 읽다 보니 많은 양의 선행 연구를 체계적으로 분류하고, 비판적으로 분석하는 연구진의 방법론과 논리적 설득력을 극대화하는 학술적 글쓰기 구조를 배울 수 있게 되었다.
해당 논문은 이집트의 Minia University 연구진(Essam H. Houssein, Amr M. Gamal, Eman M. G. Younis, Ebtsam Mohamed )을 중심으로 작성되었다.
의료 영상 AI에 XAI를 적용한 연구들을 모아서 비교, 분석하고, 문제점이랑 앞으로 방향을 정리한 리뷰 논문이다.
[0]. 요약
2016년에 시작된 디지털 혁명에 힘입어 다양한 분야에서 AI 사용이 급증하였다. 그렇지만 AI의 블랙박스 특성에 대한 우려는 여전히 상당하다. 지능형 시스템은 설명 없이 결정을 내리기 때문에 특히 의학과 같은 중요한 분야에서 심각한 문제를 야기한다.
AI가 "이 환자는 암입니다"라고 진단을 내렸다고 가정해 보자.
근데 의사가 AI한테 "왜 암이라고 생각해?"라고 물어보면 기존 AI는 대답을 못한다. 왜냐하면 숫자 계산을 엄~~ 청 많이 해서 결론만 뱉는 구조이기 때문이다.
⇒ 이것이 블랙박스의 문제다.
{1}. 왜 의료에서 심각한가?
- 일반 분야 : AI가 틀리면 → 다음에 틀리지 않도록 고쳐야 되는 불편함이 있음
- 의료 분야 : AI가 틀리면 → 사람이 죽을 수도 있음
그래서 의사, 환자, 규제기관 등이 "AI가 왜 그렇게 판단했는지 모르는데 어떻게 ㅁ디고 쓰냐?"라는 반응이다.
{2}. 해결책이 있나? → XAI
| 구분 | 기존 AI | XAI |
| 결과 | "암입니다" | "암입니다" |
| 근거 | 없음 | "이 부위가 의심스러워요" |
| 신뢰 | 낮음 | 높음 |
{3}. 의료 영상에서 어떻게 쓰이나?
의료 분야 중 영상(MRI, CT, X-ray 등)은 판독이 중요하다. XAI를 쓰면 아래와 같은 기능을 한다.
- 시각적 설명 : "이 사진의 이 부분 때문에 암으로 판단했어" (예 : *히트맵으로 표시)
- 텍스트 설명 : "종양 크기, 모양, 밀도가 기준치를 초과함"
- 예시 기반 : "비슷한 사례 100개 중 95개가 악성이었어"
? 히트맵이란
데이터의 값, 빈도, 강도 등을 색상으로 표현하여 시각화한 데이터 분석 도구이다.

[1]. 서론
{1}. 문제 제기
AI는 잘 맞추는데, 왜 맞췄는지를 못 말한다.
- 딥러닝이 종양 탐지, 장기 분할 등에서 뛰어난 성능을 보임
- 그러나 블랙박스 특성상 의료진이 근거를 검증할 수 없음
- 실제 사례로 유방암 탐지 DL 모델이 임상 시험에서 "설명 불가"로 거부를 당함
{2}. 왜 의료에서만 시각 한가?
설명 불가 → 의료진 불신 → AI 도입 거부 → 규제기관 승인 거부 →
→ 법적, 윤리적 책임 문제
- 일반 분야와 달리 의료에서 설명 가능성은 기술적 선호가 아닌
- 생명이 연결되기 때문에 설명이 필수 요소이다.
{3}. 해결책 : XAI
| 기법 | 설명 방식 |
| Grad-CAM | MRI에서 종양 영역을 히트맵으로 시각화 |
| SHAP/LIME | 각 특징이 진단에 미친 수치적 영향 제공 |
{4}. 논문의 기여
- XAI 프레임워크 분류 : 전역/지역, 사전/사후, 특징/비특징 모델 관점 정리
- 해부학적 위치 + 영상 기법별 분류 : 흉부, 뇌, MRI 위주 연구 현황 파악
- 연구 격차 발견 : 대부분 논문이 전역 설명보다 국소 설명에 집중
[1.1]. 이 논문을 쓰는 이유
"AI가 의료 영상을 분석해서 진단을 내리는 건 알겠는데, 도대체 어떻게 그런 결론을 내리는 거지?"에 대한 궁금증에서 출발한 논문이다.
딥러닝 기반 AI는 MRI, CT, X-ray 같은 의료 영상을 보고 "이건 종양입니다"라고 판단할 수 있다. 근데 문제는 왜 그런 판단을 내렸는지를 개발자, 의사 등 모두가 모른다는 거다.
그래서 해당 논문은 XAI라는 분야를 의료 영상에 적용한 연구들 300편을 정리한 리뷰 논문이다. 즉, XAI를 의료 영상에 어떻게 쓰는지 총정리한 교과서 같은 것이다.
논문이 답하려는 핵심 질문들은 아래와 같다. 질문을 보면 논문의 방향성이 보인다.
- 머신러닝이랑 딥러닝은 어떻게 다른 거야?
- AI, ML, 딥러닝, XAI 이 개념들 어떻게 연결돼?
- XAI가 정확히 뭔데?
- XAI 내부 구조가 어떻게 생겼어?
- 의료 영상 진단에서 실제로 쓰는 XAI 기법이 뭐야?
- XAI모델이 "잘 설명하고 있다"는 걸 어떻게 측정해?
- 의료 현장에 XAI를 실제로 도입하면 어떤 어려움이 있어?
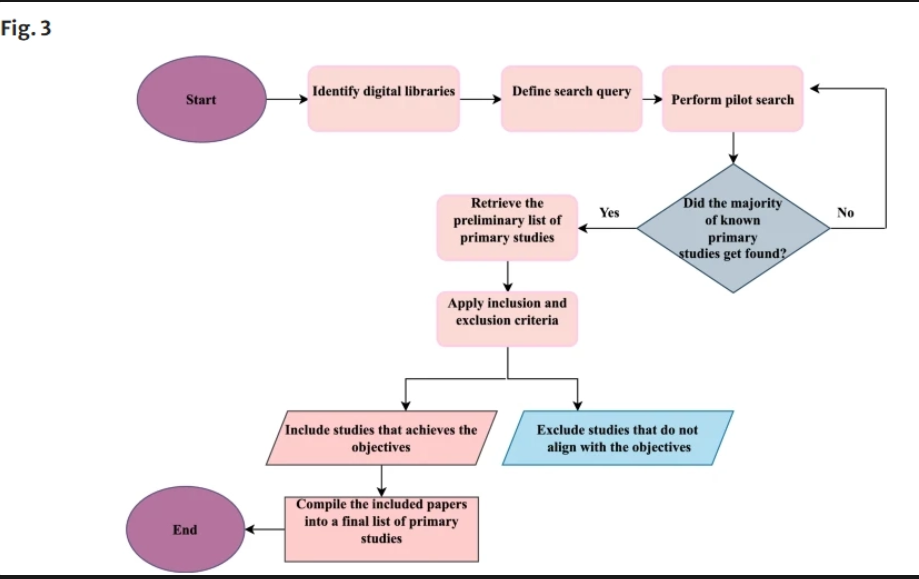
[1.2]. 논문 작성 방법
리뷰 논문은 실험을 직접 한 것이 아니라, 기존에 나온 연구들을 체계적으로 수집하고 정리하는 방식으로 작성된다. 해당 논문도 마찬가지다.
{1}. 논문 수집
PubMed, IEEE Xplore, Science Direct, Google Scholar 같은 학습 데이터베이스에서 논문을 긁어모았다.
검색 키워드는 "XAI", "딥러닝", "의료 영상", "설명 가능성" 같은 XAI와 의료 영상 관련된 키워드들이고, 최종적으로 300편을 확보하여 리뷰 논문을 작성한 것이다.
(1). 포함한 논문
- 딥러닝을 사용한 의료 영상 연구
- XAI 기법을 실제로 적용한 연구
- AI 모델의 설명 가능성, 해석 가능성을 다룬 연구
{2}. 제외한 논문
- 딥러닝 없이 전통적인 머신러닝만 쓴 연구
- 의료 영상과 관련 없는 연구
{3}. 각 논문에서 정보 추출
선별된 논문에서 아래 정보들을 뽑았다.
- 저자 / 출판 연도
- 어떤 딥러닝 모델을 사용했는지
- 어떤 XAI 기법을 적용했는지
- 어떤 의료 영상을 분석했는지
- 성능 평가는 어떻게 했는지
- 주요 결과가 뭔지
{4}. 분석하고 종합하기
추출한 정보들을 모아서 공통 패턴, 트렌드, 연구 공백 같은 걸 찾아냈다.
- "대부분의 연구가 전체적인 설명보다 특정 부위 설명(국소 설명)에 집중하고 있다"
- "CNN 모델에는 Saliency Mapping 기법이 압도적으로 많이 쓰인다"


{6}. 논문 품질은 어떻게 걸러내나?
논문의 양도 중요하지만, 질 낮은 논문이 섞이면 결론이 왜곡될 수 있다. 그래서 기준을 정했다.
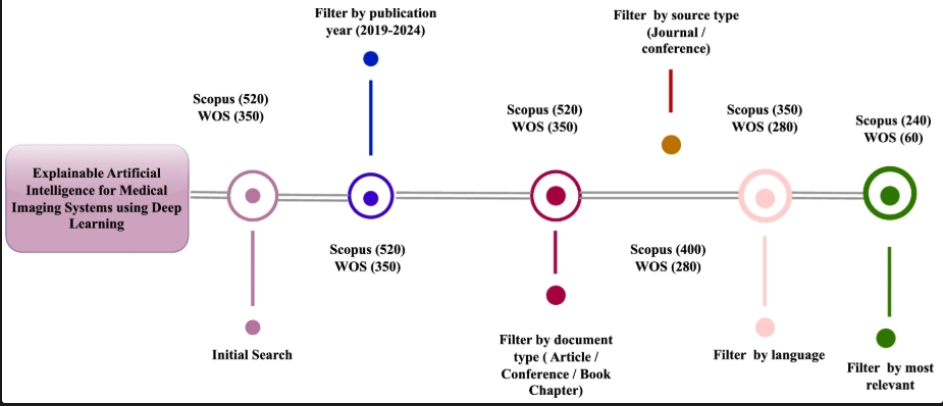
(1). 어디서 찾았나?
데이터 수집 단계에서는 PubMed, IEEE, Google Scholar 등 다양한 채널을 통해 관련 연구를 폭넓게 수집하였으나,
최종 분석 단계에서는 연구의 질적 수준과 학술적 신뢰성을 보장하기 위해
Scopus와 Web of Science(WoS)에 등재된 검증된 논문들로 범위를 한정하여 정리함
- Scopus : 520편
- WOS : 350편
- 합계 = 870편
(2). 필터링 - 4단계
1단계 : 출발 연도 필터 (2019 ~ 2024년만)
- Scopus : 520편 → 500편
- WOS : 350 vus → 340 vus
왜 2019년부터인가?
- 2019년 이전엔 XAI 연구 자체가 초기 단계였음
- 2019년 이후부터 AI 투명성, 규제, 임상 적용에 대한 관심이 폭발적으로 증가
- Transformer, 생성형 XAI 같은 최신 기술도 최근 5년 사이에 본격적으로 등장함
2단계 : 문서 유형 필터 (논문, 학회발표만)
- Scopus : 500편 → 400편
- WOS : 340편 → 280편
⇒ 블로그 글, 뉴스 기사, 보고서 같은 건 제외하고 정식 연구 논문만 남김
3단계 : 자료 유형 필터 - 학문적 가치, 신뢰도가 검증된 논문만
- Scopus : 400편 → 350편
- WOS : 280편 → 280편
4단계 : 언어 필터 (영어만)
- Scopus : 350편 → 240편
- WOS : 280편 → 60편
[1.3]. 논문의 한계
논문 저자들이 스스로 자기 논문이 완벽하지 않다고 인정하는 섹션이다.
학술 논문에서는 이런 한계를 솔직하게 밝히는 게 오히려 신뢰성을 높여준다.
논문이 빠졌을 수 있다. 열심히 찾아도 검색 과정에서 관련 논문이 일부 누락됐을 가능성이 있다.
선택 편향이 있을 수 있다. 딥러닝 + 의료 영상 + XAI라는 기준으로만 골랐기 때문에 기준 바깥의 중요한 연구가 제외됐을 수 있다.
해석이 주관적일 수 있다. 논문 300편은 사람이 분석했기 때문에 저자의 관점이 어느 정도 반영될 수밖에 없다.
[2]. eXplainable AI (XAI)
- AI가 결론만 내리는 게 아니라, 왜 그런 결론을 냈는지 사람이 이해할 수 있게 설명해 주는 AI
{1}. 언제부터 시작인가?
- 최근에 나온 개념이 아니다. 역사가 있는 개념이다.
- 1970년대 : 전문가 시스템이 "왜 이런 결론을 냈지?"라는 문제를 처음으로 인식하기 시작
- 2004년 : Van Lent 등이 "XAI"라는 용어를 처음 공식적으로 사용함 → 시뮬레이션 게임 AI의 행동을 설명하는 연구에서
- 현재 : 딥러닝이 발전하면서 XAI의 필요성이 폭발적으로 증가
{2}. 여러 기관에서 XAI를 어떻게 정의하는가?
표현은 다르지만 하나의 방향을 가리킨다.
(1). DARPA (미국 국방고등연구계획국)
→ 예측 정확도는 유지하면서, 사람이 AI를 이해하고 관리할 수 있도록 설명 가능한 모델을 만드는 것
(2). FAT_ML 워크숍 (AI 공정성 연구 그룹)
→ AI의 결정과 그 결정에 사용된 데이터를 비전문가도 이해할 수 있는 말로 설명할 수 있게 하는 것
(3). FICO (신용평가 회사)
→ 머신러닝의 블랙박스를 열어서, 고객이 AI 결정을 신뢰할 수 있도록. 정확하면서도 설명 가능한 모델을 제공하는 것
셋 다 표현은 달라도 핵심은
⇒ "AI야, 네가 왜 그런 결정을 내렸는지 사람한테 설명해 봐"이다.
{3}. XAI 구조도
┌─────────────────────────────────────────┐
│ XAI 시스템 │
│ │
│ [1. AI 모델] [2. XAI 방법] │
│ (블랙박스) → (설명 생성기) │
│ "암입니다" "왜냐하면..." │
│ │
│ ↓ ↓ │
│ 예측 결과 설명 결과 │
│ │
│ └──────┬───────┘ │
│ ↓ │
│ [UI로 사용자에게 표시] │
└─────────────────────────────────────────┘- AI 모델 : 데이터를 보고 예측값을 뱉는 부분
- XAI 방법 : 그 예측이 왜 나왔는지를 설명하는 부분
최종적으로 사용자는 두 가지를 같이 받게 된다.
예) :
- 예측 : "이 환자는 폐렴입니다."
- 설명 : "폐 오른쪽 하단 부위의 음영 패턴이 주요 근거입니다."
XAI에 대해 전 세계적으로 합의된 단 하나의 공식 정의는 없다. 그런데 모든 정의가 공통적으로 추구하는 건 하나다.
⇒ AI에 대한 두려움과 불신을 없애고, 사람과 AI 사이의 이해의 벽을 허무는 것


[2.1]. XAI가 필요한 이유
AI가 내린 결정을 이해하고, 통제하고, 개선하고, 새로운 걸 발견하기 위함.
논문은 이걸 4가지 핵심 이유로 나눠서 설명한다.
{1}. 정당성 - 왜 그런 결정을 내렸어?
의료 진단 같은 중요한 분야에서 AI가 결론을 내리면, 반드시 근거가 있어야 한다.
- 기존 AI : "이 환자는 암입니다" 끝
- XAI "이 환자는 암입니다 ⇒ 오른쪽 폐 하단 음영 패턴이 주요 근거입니다"
단순한 편의 문제가 아니라 법적으로도 의무화되고 있다.
유럽연합에서 시행되고 있는 EU 개인정보보호법은 2018년부터 "AI가 내 삶에 영향을 주는 결정을 내렸다면 나는 그 이유를 설명받을 권리가 있다"는 조항이 포함돼 있다.
즉, XAI가 법적 요건이 된 셈이다.
{2}. 제어 - AI가 이상하게 작동하면 멈출 수 있어야 해
AI를 설명할 수 있다는 것은 AI를 통제할 수 있다는 뜻이다.
- 설명 가능성 = "왜 그렇게 했어?" → 이유를 알 수 있음
- 제어 가능성 = "그럼 어떻게 고쳐?" → 행동을 바꿀 수 있다.
XAI는
- AI의 취약점이나 결함을 미리 발견할 수 있다.
- 문제가 생겼을 때 빠르게 수정할 수 있다.
- AI가 윤리 기준, 안전 요건을 벗어나지 않게 통제할 수 있다.
논문에서는 아래처럼 정리를 했다.
- "설명 가능성은 '왜'를 제공하고, 제어 가능성은 '어떻게'를 제공한다. 둘이 합쳐져야 책임감 있는 AI가 된다.
{3}. 개선 - AI의 약점을 알아야 고칠 수 있다.
AI가 왜 틀렸는지도 모르면, 어떻게 고쳐야 할지도 모른다.
- XAI 없을 때 AI가 틀리면 : 왜 틀렸는지 모름 ⇒ 개선 불가
- XAI 있을 때 AI가 틀림 : 어떤 부분이 문제인지 파악 ⇒ 개선 가능
XAI는 AI 시스템의 내부를 들여다볼 수 있게 해 줘서, 지속적인 성능 향상이 가능하다.
{4}. 발견 - 설명하다 보면 새로운 걸 알게 돼
AI가 왜 그런 결정을 내렸는지 설명하는 과정에서, 사람이 몰랐던 새로운 패턴이나 지식이 발견되는 경우가 있다.
예) :
AI가 특정 의료 영상에서 암을 탐지할 때, XAI로 분석해 보니 의사들이 미처 주목하지 않았던 새로운 병변 패턴이 발견되는 경우
즉, XAI는 단순히 AI를 설명하는 도구를 넘어서, 새로운 의학적 발견을 이끄는 도구가 될 수 있다.
네 가지를 표로 정리하면 아래와 같다.
| 이유 | 핵심 질문 | 설명 |
| 정당성 | 왜 그런 결정을 했어? | 근거를 설명해서 신뢰를 얻음 |
| 제어 | 잘못되면 어떻게 멈춰? | AI 동작을 감시하고 통제 |
| 개선 | 어떻게 더 잘할 수 있어? | 약점 파악 → 성능 향상 |
| 발견 | 설명하다가 뭔가 새로 알았어? | 몰랐던 지식, 패턴 발견 |

[2.2]. 의료 분야에서 XAI의 필요성
XAI는 금융, 마케팅, 자율주행 등 다양한 분야에서 쓰이지만 의료는 다른 분야들과 다르다.
AI가 틀리게 되면
- 금융 : 돈을 잃는다
- 마케팅 : 광고 효율이 떨어진다.
- 의료 : 사람이 죽을 수 있다.
오진 하나가 돌이킬 수 없는 결과로 이어질 수 있기 때문에, 의료에서 XAI는 선택이 아닌 필수다.
{1}. 필요한 이유 네 가지
(1). 의사결정 지원
의사가 AI의 판단을 그냥 믿고 따를 수 없다. 왜 그런 결론을 냈는지 이해해야 최종 판단을 내릴 수 있다.
XAI가 있으면 → 의사가 AI의 근거를 검토하고 → 더 나은 치료 결정을 내릴 수 있다.
(2). 정확성 확보
의료에서 정확성은 선택 사항이 아니다. XAI는 AI가 어떤 근거로 판단했는지를 보여주기 때문에 잘못된 판단을 사전에 걸러낼 수 있다.
(3). AI 모델 지속 개선
AI가 왜 틀렸는지 알아야 고칠 수 있다. XAI는 AI의 약점을 정확히 짚어줘서 더 안전하고 신뢰할 수 있는 모델로 발전시킬 수 있다.
(4). 최신 지식 습득
XAI를 통해 AI가 어떤 패턴을 근거로 판단하는지 보다 보면, 의료진이 몰랐던 새로운 의학적 인사이트를 얻기도 한다.
{2}. 구체적인 이유
(1). 임상 신뢰와 도입
의사들은 이유를 모르는 AI 판단을 믿지 않는다.
예를 들어 단순히 CT 결과로 특정 부위가 의심된다 + 왜 의심되는지 시각적으로 강조하면 의사가 신뢰할 수 있게 된다.
(2). 규제 준수
의료 AI은 미국 식품의약국, EU의 개인정보보호법의 설명받을 권리 같은 엄격한 법적 기준을 통과해야 한다.
XAI가 없으면 의료 분야에서의 AI는 사용할 수 없다.
(3). 오류와 편향 탐지
훈련 데이터가 편향되면 AI도 편향된 판단을 내린다. XAI는 AI가 어떤 특징에 주목하는지 보여줘서 이런 편향을 발견하고 수정할 수 있게 해 준다.
(4). 환자 중심 소통
AI의 판단 근거를 시각화하는 XAI는 의사의 전문적 식견에 객관적 지표를 더해주는 역할을 합니다. 의사가 AI의 분석 영역을 직접 확인하고 환자에게 설명함으로써, "기계가 시켰다"는 식의 일방적 전달이 아닌 "데이터에 기반한 협력적 진단"이 가능해진다. 결과적으로 환자는 시각화된 근거를 통해 자신의 상태를 더 명확히 이해하게 되며, 이는 의료 서비스에 대한 신뢰도 향상으로 직결된다.
[3]. XAI, 실제로 어디에 쓰이고 있나?
XAI는 의료 분야에만 쓰이는 게 아니다. AI에 의존하는 거의 모든 부야에서 활용되고 있다.
[3.1]. 분야별 XAI 활용

의료 분야는 XAI가 가장 활발하게 연구되는 분야이다. 구체적인 사례는 아래와 같다.
{1}. 의료 및 진단
(1). 암 진단
영상 데이터 + 유전 정보 + 임상 데이터를 합쳐서 "왜 이게 암인지"를 포괄적으로 설명하는 멀티모달 XAI 시스템이 개발되고 있다.
(2). 흉부 X-ray(폐렴, COVID-19 등)
*Grad-CAM으로 의심 부위를 히트맵으로 강조 → 방사선과 의사가 AI 판단을 눈으로 검증 가능
? Grad-CAM란
MRI 사진을 보고 AI가 뇌종양입니다.라고 판단했을 때,
AI가 사진에 어느 부분을 보고 그런 판단을 내렸는지 색깔 히트맥으로 시각화해 주는 기법이다.
원본 MRI 사진 Grad-CAM 적용 후
┌─────────────┐ ┌─────────────┐
│ │ │ 🔵🔵 │ ← 별로 안 봄
│ 뇌 사진 │ → │ 🟡🔴🔴 │ ← 여기 집중!
│ │ │ 🔴🔴🟡 │ ← 종양 의심 부위
│ │ │ 🔵🔵 │
└─────────────┘ └─────────────┘
🔴 빨강 = AI가 가장 많이 주목한 부분
🟡 노랑 = 중간 정도 주목
🔵 파랑 = 거의 안 봄
Grad-CAM은 CNN의 마지막 레이어를 역으로 분석한다.
AI가 "뇌종양"이라고 판단할 때
↓
어떤 픽셀들이 그 판단에 얼마나 기여했는지
↓
기여도가 높을수록 빨간색으로 표시(3). 유방암 진단
- Grad-CAM : 유방 촬영술에서 종양 의심 영역 하이라이트
- SHAP : 종양 크기, 유전 표지자 등 환자별 특징 분석 → 맞춤 치료 계획 수립
(4). 병리 영상 분석
Attention 기반 모델이 조직 이미지에서 비정상 세포 영역을 강조 → 병리학자가 양성/악성을 더 높은 확신으로 구분
(5). 당뇨병성 망막증
Saliency Map으로 안저 이미지의 비정상 망막 영역 강조 → 안과 전문의가 부족한 환경에서도 일반의가 AI의 판단 근거를 직관적으로 확인하고 검증할 수 있도록 지원함. 이는 전문 인력이 부족한 의료 현장에서 AI 진단 시스템의 실질적인 활용성을 높이는 핵심 요
(6). 수술 의사결정 지원
Attention 메커니즘이 수술 전 계획 단계에서 위험한 해부학적 부위를 미리 강조 → 외과의에게 잠재적 위험 사전 안내
{2}. 금융 및 위험 평가
- 활용 영역 : 위험 평가, 사기 탐지, 투자 결정
금융 AI도 블랙박스 문제가 심각하다. 왜 대출을 거절했는지, 왜 이게 사기 거래인지 설명을 못하면 규제 기관에서 승인이 안 난다.
XAI를 쓰면
- 규제 기관, 감사인이 AI 판단 근거를 이해할 수 있다.
- 차별적이거나 편향된 판단 패턴을 미리 발견하고 수정 가능하다.
{3}. 자율주행, 로봇 공학
- 활용 영역 : 자유주행 자동차, 로봇 보조 수술
"왜 차가 멈췄지?", "로봇이 왜 이 동작을 선택했지?"
이건 설명할 수 없으면 사람이 AI 시스템 믿고 함께 일할 수 없다. XAI가 의사결정 과정을 설명해 줌으로써
- 인간, AI 협업이 가능함
- 오류를 빠르게 감지하고 복구할 수 있다.
{4}. 법률, 규제
활용 영역 : 문서 분석, 계약 검토, 규정 준수 모니터링
법원에서 AI가 "이 계약은 위법이다"라고 판단했는데 이유를 못 대면 법적으로 의미가 없다.
XAI는
- 변호사, 판사 등 재판하는 사람들이 AI 법적 판단의 근거를 이해할 수 있고
- 공정성, 책임성을 법적으로 보장할 수 있다.
[3.2]. XAI를 사용한 다른 분야의 교훈
의료 영상 XAI는 굳이 처음부터 개발할 필요가 없다. 다른 분야에서 이미 써본 것들을 가져다 쓰면 된다.
분야별 교훈은 아래와 같다.
{1}. 금융 → 표준화된 평가 기준을 만들어라
금융에서는 SHAP, LIME 같은 기법으로 사기 탐지, 신용 평가의 근거를 설명하고 있다.
중요한 건 "누가 봐도 같은 기준으로 해석할 수 있는 표준 프레임워크"를 만들었다는 것이다.
이것을 의료에 적용하면
- XAI 설명을 의사마다 다르게 해석하지 않도록 일관된 평가 기준이 필요하다
{2}. 자율주행 → 실시간으로 설명할 수 있어야 해
자율주행 차량을 Grad-CAM, Attention 같은 기법으로 복잡한 데이터를 실시간으로 설명한다.
우전 중에 "왜 브레이크를 밟았는지" 즉각 알 수 있어야 하기 때문에
의료에 적용하면
- 응급 상황에서도 AI 판단을 즉각적으로 설명할 수 있어야 한다.
{3}. 법률 → 책임 소재를 추적할 수 있어야 해
법률 AI는 규칙 기반 시스템과 반사실적 설명을 써서 "왜 이 결정을 내렸는지" 추적 가능하게 설계되어 있다.
법정에서 "AI가 그렇게 판단했어요"라고만 하면 아무 의미가 없다. 반드시 근거가 있어야 한다.
반사실적 설명은 "만약 ~했다면?"이라고 거꾸로 따져보는 것이다.
예) :
"만약 종양 크기가 더 작았다면 AI가 양성으로 판단했을까?"
→ 이렇게 따져봄으로써 AI가 무엇을 근거로 악성이라 판단했는지 역으로 추적할 수 있다.
의료에 적용하면
- AI가 오진을 했을 때 "AI가 어떤 근거로 그런 판단을 내렸는지" 거슬러 올라가서 추적할 수 있어야 한다는 것이다.
- 즉, 책임이 AI에 있는지, 데이터에 있는지, 의사의 판단에 있는지를 명확히 가릴 수 있다.
{4}. 전자상 거래 → 환자 개인에게 맞춤형 설명을 제공하라
쇼핑몰 AI가 "당신의 구매 이력 때문에 이 제품을 추천해요"처럼 개인화된 설명을 해준다.
의료에 적용하면
- "당신의 나이, 병력, 영상 패턴 때문에 이런 질답을 내렸습니다."처럼 환자 개인에 맞춤 설명이 필요하다.
{5}. 교육 → 누구나 이해할 수 있게 설명하라
교육 AI는 학생의 수준에 맞춰 쉽고 직관적인 설명을 제공하는 걸 중시한다.
의료에 적용하면
- AI 전문가가 아닌 의사, 환자도 이해할 수 있는 직관적인 설명이 필요하다.
표로 정리하면 아래와 같다.
| 분야 | 교훈 | 의료 적용 방향 |
| 금융 | 표준화된 평가 기준 | XAI 해석의 일관성 확보 |
| 자율주행 | 실시간 설명 | 응급 상황에서도 즉각 설명 |
| 법률 | 책임 추적 가능 | AI 오진 시 책임 소재 명확화 |
| 전자상거래 | 개인화 설명 | 환자별 맞춤 진단 근거 제공 |
| 교육 | 접근성, 직관성 | 비전문가도 이해 가능한 설명 |
[3.3]. XAI 프레임워크 - XAI 기법들을 어떻게 분류해?
일단 먼저 분류가 필요한 지부터 생각해 보자
XAI 기법이 워낙 다양하다 보니, "이 기법은 어떤 상황에 써야 해?"를 정리할 기준이 필요하다. 그래서 연구자들이 여러 기준으로 XAI를 분류하는 프레임워크를 만들었다.
근데 이 분류는 절대 기준이 아니다. 기법에 따라 여러 카테고리를 동시에 속하거나, 분류 체계마다 다르게 묶이는 경우도 있다.
{1}. 분류 기준
(1). Model-Specific(모델 특화형) vs Model_Agnostic(모델 비특이형)
비특이형이란 특정 AI 모델 구조에 종속되지 않고, 어떤 모델에도 적용 가능한 XAI 기법을 말한다.
- 모델 특화형 : 특정 AI 모델에서만 작동 → 예 : CNN 전용 Grad-CAM
- 모델 비특이형 : 어떤 AI 모델에든 적용 가능 → 예 : SHAP, LIME
(2). Global vs Local
- Global Explainability : AI 모델 전체의 작동 방식을 설명 → 예 : "이 모델은 전체적으로 폐 음영 패턴을 가장 중시해"
⇒ 모델의 전반적인 학습 경향
- Local explainbility : 특정 예측 하나를 설명 → 예 : "이 환자를 폐렴으로 진단한 이유는 오른쪽 폐 하단의 음영 때문이야"
⇒ 특정 환자 한 명에 대한 설명
(3). Intrinsic(모델 기반) vs Post-hoc(사후 분석)
- Intrinsic : 처음부터 설명 가능하게 설계된 모델 → 화이트박스 모델들
- Post-hoc : 이미 만들어진 블랙박스 모델에 설명을 붙이는 방식 → Grad-CAM, SHAP, LIME
기법들을 좀 더 자세히 알아보자
{2}. Model-Specific vs Model-Agnostic
(1). Model-Specific
특정 AI 모델 구조에 맞게 설계된 기법이다. 모델 내부 구조를 직접 활용하기 때문에 정확하고 세밀한 설명이 가능하다.
- 장점 : 해당 모델에 최적화된 정밀한 설명 제공
- 단점 : 호환되는 모델에만 적용 가능 ⇒ 범용성 없음
예) :
- CNN : Grad-CAM
- RNN : Integrated Gradients
- 의사결정 트리 : 신용 평가 설명
(2). Model-Agnostic
모델을 블랙박스로 취급하고, 입력과 출력만 분석해서 설명을 생성한다. 내부 구조에 접근하지 않기 때문에 어떤 모델에든 갖다 붙일 수 있다.
- 장점 : 어떤 모델에도 적용 가능 ⇒ 범용성 높음
- 단점 : 계산 비용이 많이 들고, 모델 특화형보다 정확도가 떨어질 수 있음
예) :
- SHAP
- LIME
{2}. Global vs Local
(1). Global
모델 전체의 동작 방식을 설명하는 기법이다.
"이 AI는 전반적으로 어떻게 판단하는가?"에 답한다.
활용 예시) :
- 어떤 특징이 모델 성능에 가장 크게 기여하는가?
- 편향 식별
- 역학 연구에서 특징 기여도 분석
기법 예시) :
- 특징 중요도 분석
- 부분 의존성 플(PDP)
- 단점 : 개별 예측을 설명하기엔 세밀함이 부족함
(2). Local
특정 예측 하나를 설명하는 기법이다.
"이 환자를 왜 암으로 진단했는가?"에 답한다.
활용 예시) :
- 방사선학 환자 개별 진단
- 대출 승인/거절 이유 설명
- 사기 거래 탐지
기법 예시) :
- 반사실적 설명 : "종양 크기가 달랐다면 결과가 바뀌었을까?"
- Saliency Map : 특징 사례에서 중요한 픽셀 강조
- 단점 : 전체 데이터셋을 일반화하기 어려움
{3}. Ante-hoc vs Post-hoc
(1). Ante-hoc - 사전 예측
처음부터 설명 가능하게 설계된 모델이다. 구조 자체가 투명해서 별도의 설명 도구가 필요 없다.
예) :
- 의사결정 트리
- 선형 회귀
- 규칙 기반 시스템
장점 :
- 구조 자체가 투명해서 이해하기 쉽다.
- 실시간 의사결정에 적합
단점 :
- 복잡한 문제에서 성능, 확장성 한계
(2). Post-hoc
학습 후 모델 결과의 모호성을 설명하려 한다.
이미 학습된 블랙박스 모델에 설명을 붙이는 방식이다.
딥러닝처럼 복잡한 모델에 주로 사용된다.
예) :
- Grad-CAM
- SHAP
장점 :
- 고성능 딥러닝 모델에도 적용 가능
- 후향적 모델 검증에 유용
단점 :
- 모델의 진짜 내부 논리를 완전히 못 잡을 수 있음
- 지나친 단순화 위험

| 기법(영문) | 기법(한글) | 색깔 | 지표 의미 |
| Scalability | 확장성 | 검정 | 대용량 데이터나 복잡한 모델에도 잘 작동하는가 |
| Precision | 정밀도 | 진한 회색 | 설명이 얼마나 정확하고 세밀한가 |
| Applicability | 적용 가능성 | 중간 회색 | 다양한 상환, 도메인에 얼마나 용적으로 쓸 수 있는가 |
| Overali Strength | 전반적 강점 | 진한 파랑 | 모든 지표를 종합한 전체 성능 |
| Flexibility | 유연성 | 파랑 | 다양한 모델, 데이터 유형에 얼마나 잘 적응하는가 |
| Fidelity | 충실도 | 하늘색 | AI 모델의 실제 내부 동작을 얼마나 정확히 반영하는가 |
| Interpretability | 해석 가능성 | 연한 파랑 | 사람이 설명을 얼마나 쉽게 이해할 수 있는가 |
| Use Case Coverage | 사용 사례 범위 | 네이비 | 얼마나 많은 분야, 문제 유형에 적용 가능한가 |

{4}. 문제 유형별 XAI 정리
| 문제 유형 | 설명 | 의료 적용 예시 |
| 분류 | 데이터를 정해진 범주로나눔 | "종양 있음 / 없음" |
| 회귀 | 연속적인 수치 예측 | 생존을 예측 |
| 분할 | 이미지를 의미 있는 영역으로 나눔 | MRI에서 종양 영역 분리 |
| 탐지 | 특정 객체, 이벤트 식별 | CT에서 종양 위치 찾기 |
| 클러스터링 | 유사 데이터 그룹화 | 환자 유형 분류 |
| 예측 | 과거 데이터로 미래 값 추정 | 재발 위험도 예측 |
{5}. 설명 유형별 XAI 정리
| 설명 유형 | 방식 | 예시 |
| 특징 기반 | 중요한 입력 특징에 점수를 매김 | 특징 중요도, Saliency Map |
| 예시 기반 | 비슷한 사례를 보여줌 | 사례 기반 추론, 프로토타입 |
| 아키텍처 수정 | 설명 가능성을 모델에 직접 내장 | Attention 매커니즘, 하이브리드 모델 |
| 시각적 설명 | 그래픽으로 표현 | 히트맵, 활성화 맵, Saliency Map |
| 비시각적 설명 | 텍스트, 통계로 표현 | 텍스트 설명, 보조 통계 지표 |
XAI 기법은 하나가 모든 상황에 최적인 것이 아니다. 어떤 모델을 사용하는지, 전체를 보고 싶은지, 개별 예측을 보고 싶은지, 어떤 문제를 푸는지에 따라 맞는 기법이 달라진다.
[3.4] XAI가 기존 AI와 다른 점
기존 AI는 결과만 주지만, XAI는 결과 + 근거를 함께 준다.
{1}. XAI가 제공하는 도구
(1). Saliency Map (살리언시 맵)
Grad-CAM 같은 기법으로 "AI가 이미지의 어느 부분을 보고 판단했는지"를 시각화함
예) :
- MRI : 종양 의심 영역을 히트맵으로 강조
- CT : 폐 이상 부위를 색깔로 표시
방사선과 의사가 AI 판단을 눈으로 직접 검증할 수 있다.
(2). Feature Attribution (특징 기여도 분석)
SHAP, LIME 같은 기법으로 "어떤 특징이 얼마나 영향을 미쳤는지"를 수치로 설명해 준다.
예) :
- 병변 크기가 판단에 40% 기여했고, 병변 모양이 35% 기여했다"
의사의 임상 전문 지식과 AI 판단이 일치하는지 확인할 수 있다.
(3). 실제 성과 사례
Deep SHAP으로 피부암을 분류한 연구에서 97% 정확도를 달성하면서도 임상 검증용 해석 가능한 히트맵을 함께 제공했다.
즉, 성능도 잡고, 설명도 잡았다.
{2}. AI vs XAI 표
| 항목 | 기존 AI | XAI |
| 투명성 | 블랙박스 | 의사결정 과정 공개 |
| 신뢰 | 근거 없음 | 근거 있음 → 신뢰 가능 |
| 책임성 | 추적 불가 | 판단 근거 추적 가능 |
| 오류 탐지 | 왜 틀렸는지 모름 | 어디서 틀렸는지 파악 |
| 임상 적용 | 위 사항들 때문에 의사가 꺼림 | 검증 가능해서 채택 가능 |
XAI는 단순히 "설명을 추가"하는 것이 아니다. 의료 현장에서 신뢰, 책임, 오류 수정 모두를 가능하게 하는 핵심 도구이다.
[4]. 의료 영상 진단을 위한 XAI 기술
{1}. XAI 기술, 얼마나 빠르게 발전하고 있는가?
최근 XAI 분야는 급속도로 성장하면서 다양한 기술들이 쏟아져 나오고 있다. 특히 주목할 만한 발전은 두 가지가 있다.
(1). 멀티모달 XAI 등장
- 영상 + 텍스트 + 표 형식 데이터를 함께 분석
⇒ 암 진단 같은 복잡한 케이스에서 정확도 향상
(2). 새로운 평가 지표 개발
- "이 XAI 설명이 얼마나 유용하고 신뢰할 수 있나?"를 수치로 측정하는 방법들이 생겨남
{2}. 문제점
기술은 많아졌는데, 오히려 "어떤 기법을 써야 하는가?"라는 어려움이 생겨버렸다.
선택지가 너무 많아서 실무자들이 혼란스러운 상황이다.
이를 해결하기 위해 Retzlaff 등의 연구자들 의사결정 프레임워크를 제시했다.
- 모델 학습 끝남 : Post-hoc 방식 선택 (Grad-CAM, SHAP, LIME 등 블랙박스 모델)
- 처음부터 설계해야 함 : Ante-hoc 방식 선택 (의사결정 트리 등 화이트박스 모델)
{3}. 섹션 4에서 다루는 XAI 기법
| 유형 | 설명 방식 | 예시 |
| 시각적 | 이미지로 설명 | Grad-CAM 히트맵 |
| 텍스트 기반 | 글로 설명 | 집단 근거 텍스트 |
| 예시 기반 | 유사 사례로 설명 | 비슷한 과거 환자 사례 제시 |
{4}. 그림 설명
그림 11은 XAI 기법 13가지를 5개 의료 영상 분야에 적용했을 때 성능이 얼마나 나오는지 비교한 것이다.

(1). 축
- 가로축 (x) : 의료 영상 적용 분야 5가 (뇌, 심혈관, 피부, 근골격계, 위장관)
- 세로축 (y) : 성능 (0~100%)
- 막대 색깔 : 각각 다른 XAI 기법
(2). 적용 분야
- Brain : MRI / CT
Cardiovascular : OCT / CT - Skin : 사진
- Musculoskeletal : X-ray / MRI
- Gastrointestinal : 내시경
(3). 표로 정리
| 기법 | 색깔 | 설명 |
| Grad-CAM | 검정 | CNN의 마지막 레이어를 분석해 예측에 중요한 이미지 영역을 히트맵으로 시각화 |
| SHAP | 진한 회색 | 게임 이론 기반으로 각 특징이 예측에 얼마나 기여했는지 수치로 표현 |
| LIME | 중간 회색 | 특정 예측 하나를 주변 데이터로 근사해 로컬 설명 제공 |
| Integrated Gradients | 진한 파랑 | 입력 특징별 기여도를 gradient 적분으로 계산해 시각화 |
| Deconvolution | 파랑 | CNN의 역방향 연산으로 각 픽셀이 예측에 미친 영향을 시각화 |
| DeepLIFT | 하늘색 | 기준값 대비 입력값의 변화가 출력에 미치는 영향을 레이어별로 역전파 |
| Attention Mechanism | 연한 파랑 | 모델이 입력의 어느 부분에 집중했는지 가중치로 시각화 |
| Class Activation Maps | 네이비 | 특정 클래스 예측에 기여한 이미지 영역을 활성화 맵으로 표시 |
| Saliency Maps | 중간 파랑 | 입력 픽셀의 미세한 변화가 출력에 미치는 영향을 gradient로 시각화 |
| 기법 | 색깔 | 설명 |
| Occlusion Sensitivity | 청록 | 이미지 일부를 가렸을 때 예측이 어떻게 바뀌는지 중요 영역 파악 |
| Counterfactual Explanation | 진한 청색 | "입력이 이렇게 달랐다면 결과가 바뀌었을까?"로 설명 |
| Prototype Selection | 연한 하늘색 | 예측 결과와 가장 유사한 대표 사례를 찾아서 설명 |
| Feature Ablation | 연한 청록 | feature을 하나씩 제거하면서 예측 변화를 측정해 feature 중요도 파악 |
[4.1] 시각적 설명 - 이미지로 설명하는 XAI
CAM(Class Activation Mapping)은 의료 영상 분석에서 가장 많이 쓰이는 시각적 XAI 기법이다.
AI가 이미지에서 어느 부분을 보고 판단했는지 시각적으로 강조해 주는 기법
{1}. 역전파 기반 접근 방식
역전파..?
AI가 예측을 내릴 때
이미지에서 결론을 도출한 것을 전파라고 한다. 이와 반대로
결론에서 이미지의 어떤 픽셀이 결론에 영향을 줬는지 역분석하는 것이 역전파이다.
{2}. 역전파 기법
(1). Deconvolution
CNN이 이미지를 분류할 때
중간 레이어에서 어떤 특징을 잡아냈는지 픽셀 수준으로 역시 각화 하는 기법이다.
(2). Guided Backpropagation
역전파에 방향성(가이드)을 추가해서
더 선명하고 정확한 Saliency Maps을 생성한다.
CNN이 학습한 특징을 더 뚜렷하게 표시한다.
(3). Gradient-based
각 픽셀이 최종 결과에 얼마나 기여했는지
기울기(gradient) 값으로 계산해서 시각화
{3}. 실제 의료 적용 사례
(1). 뇌졸중 병변 분할 (CT 스캔)
*3D U-Net 모델에 기울기 기반 방법을 적용해서 각 *복셀이 분할 결과에 얼마나 기여하는지 시각화
XAI 적용 전/후 성능 향상 결과 :
- *Dice 계수: 0.44 → 0.54
- 민감도 : 0.80 → 1.00
- 특이도 : 0.90 → 0.98
- 민감도 : 실제 양성인 것을 AI가 양성으로 얼마나 잘 잡아냈는가?
- 특이도 : 실제 음성인 것을 AI가 음성으로 얼마나 잘 걸러냈는가?
? 3D U-Net : 의료 영상 분석에서 MRI나 CT 스캔과 같은 3차원 볼륨 데이터의 픽셀/복셀 단위 분할을 위해 설계된 딥러닝 모델
? 복셀 : 부피와 픽셀의 합성어로, 3차원 공간에서 덩어리 형태의 정보를 가진 가장 작은 단위
? Dice 계수 : AI가 찾아낸 병변 영역이 실제 병변 영역과 얼마나 겹치는지 측정하는 지표로 1에 가까울수록 정확하다.
(2). 심장 CT - 관상동맥 석회화 추정
deconvolution으로 CT 이미지 슬라이스에서 *석회화 추정에 영향을 준 특정 영역을 식별
? 석회화 : 몸속 조직에 칼슘염이 비정상적으로 쌓여 딱딱해지는 현상
(3). 뇌파(fMRI) - 행동 작업 분류
심층 전이 학습(DTL) 기반 신경 디코더에 *ImageNet 사전학습 모델을 결합해서 행동 분류
? ImageNet : 컴퓨터 비전 및 AI 연구를 위해 구축된 대규모 시각 데이터베이스
{4}. 역전파 기법 정리
| 기법 | 원리 | 특징 |
| Deconvolution | CNN 레이어를 역으로 분석 | 중간 특징 레이어 시각화 |
| Guided Backpropagation | 역전파에 방향성 추가 | 더 선명한 살리언시 맵 |
| Gradient-based | 픽셀별 기여도를 기울기로 계산 | 본할 정확도 향상에 효과적 |
{5}. CAM (Class Activation Map)
(1). CAM이란
기존 CNN은 이미지를 분류할 때 마지막 완전 연결 계층(Fully Connected Layer)을 쓴다. 근데 이게 블랙박스라 "어디를 보고 판단했는지" 알 수가 없다.
CAM은 이걸 전역 평균 폴링(*GAP)으로 대체해서 해결함
기존 CNN
이미지 → 컨볼루션 레이어들 → 완전 연결 계층 → "암입니다"
↑
블랙박스 구간
CAM 적용
이미지 → 컨볼루션 레이어들 → 전역 평균 풀링 → "암입니다"
↑
+ 어느 영역이 중요한지 히트맵 생성핵심은 *Bounding Box 없이도 객체 위치를 스스로 학습할 수 있다.
? Bounding Box란
"이 부분이 종야이야"라고 사람이 직접 네모 박스로 표시해 주는 라벨링 작업이다. 이게 시간과 비용을 많이 먹는데 CAM은 알아서 하기 때문에 Bounding Box가 필요 없다.
? GAP(Global Average Pooling)
일반 Pooling이 이미지를 부분 부분 축소한다면, GAP는 feature map 전체를 하나의 숫자로 압축한다.
예를 들어 8x8 feature map이 있으면
전체 64개 값의 평균 ⇒ 숫자 1개
즉, 필터가 20개 있다면 ⇒ 숫자 20개짜리 벡터 하나가 나온다.
GAP가 CAM에서는 왜 쓰이는가?
기존 CNN은 Flatten에서 Fully Connected Layer로 넘어가면 공간 정보가 사라지기 때문에 어느 위치 때문에 이 판정이 나왔는지 추적이 불가능해진다.
GAP는 FC Layer 대신 사용해서 공간 정보를 최대한 유지한 채 압축한다. 덕분에 나중에 역으로 추적해서 "이 영역을 보고 고양이라고 판단했다"는 히트맵을 만들 수 있다.
즉, FC Layer가 공간 정보를 뭉개버리면, GAP는 공간 정보를 살린 채 요약한다. CAM이 설명 가능한 이유의 핵심이다.
(2). 의료 적용 사례
1. 파킨슨병 진단 (*3D MRI)
*3D CNN으로 뇌 전체 MRI를 분석하고, *3D CAM으로 의사결정 과정을 시각화하였다.
결과: 모델이 파킨슨병 진단 시
흑질 영역(SNc)에 집중한다는 것을 발견의사들이 임상적으로 알고 있던 것과 일치했기 때문에 XAI의 신뢰도가 상승했다.
? 3D MRI : 뇌를 얇게 층층이 촬영한 입체 영상
? 3D CNN : 3D 영상을 분석할 수 있게 확장된 CNN(*3D convolution 연산을 이용한 접근법)
? 3D CAM : 3D 영상에서 어느 부위가 중요한지 입체적으로 표시하는 히트맵
? 3D convolution : 2D 이미지에서 시간축이나 깊이축을 추가해서 3차원 데이터 특징을 추출하는 연산 기법
2. 당뇨병성 망막증 진단 (Messidor - 2 데이터셋)
여러 최첨단 모델을 CAM으로 비교 분석한 결과
분류 성능 1위: NASNet
→ 정확도, 정밀도, 재현율, F1 점수 모두 약 95%
위치 파악 성능 1위: VGG19
→ IoM 평균 0.45"분류를 잘하는 모델!= 위치를 잘 찾는 모델" 파라미터가 많을수록 분류는 잘하지만, 위치 파악은 오히려 떨어지는 경우가 있다.
(3). 다중 스케일 CAM
1. CAM의 문제점
의료 영상에는 아래 같은 상황이 자주 발생한다.
- 내시경 사진 전체 크기 : 매우 큼
- 그 안의 모세혈관 패턴 : 매우 작음
일반 CAM은 이미지 전체 기준으로 히트맵을 만든다. 그러다 보면 작은 병변은 히트맥에서 묻힌다.
지도 앱으로 설명하면
- 위성 뷰 (전체 보기) : 도시 전체가 보임 ⇒ 골목길은 잘 안 보임
- 거리 뷰 (가까이 보기) : 골목길이 선명하게 보임 ⇒ 도시 전체는 못 봄
그럼 실제로 어떻게 작동함?
- 해상도 1 (크게 보기) : 큰 병변 탐지
- 해상도 2 (중간 보기) : 중간 병변 탐지
- 해상도 3 (작게 보기) : 작은 병변 탐지
세 결과를 합쳐서 최종 히트맵 생성
즉, 이미지를 여러 배율로 동시에 분석해서, 크고 작은 병변을 모두 놓치지 않는 CAM이다.
2. 실제 적용 사례
- 1. 내시경 영상 분석
전체 이미지보다 훨씬 작은 모세혈과 패턴을 정확하게 강조하기 위해 다양한 해상도로 CAM을 추출
-2. 녹내장 진단 - EAMNet
다중 스케일 CAM을 적용한 임상 해성 가능 CNN 아키텍처
구조: M-LAP + ResNet
+ 3개의 전역 평균 풀링(GAP) 레이어
(각각 다른 해상도 담당)
결과: 분류 성능 유지 + 해상도 대폭 향상(4). 정리
| 구분 | 일반 CAM | 다중 스케일 CAM |
| 분석 해상도 | 단열 | 여러 해상도 동시 |
| 작은 병변 탐지 | 놓칠 수 있음 | 탐지 가능 |
| 복잡도 | 낮음 | 높음 |
| 적합한 상황 | 변변이 크고 뚜렸할 때 | 병변 크기가 다양할 때 |
{5}. 기울기 가중 CAM(Grad-CAM) - CAM의 업그레이드 버전
CAM랑 뭐가 다른가?
- CAM : *전역 평균 폴링(GAP)이 있는 CNN에서만 작동 ⇒ 구조 제약이 있음
- Grad-CAM : GAP 없이도 작동 ⇒ 어떤 CNN에든 적용 가능 + Post-hoc 로컬 설명 제공
여기서 한 단계 더 발전한 게 Guided Grad-CAM이다.
- Guided Grad-CAM = Grad-CAM + 가이드 역전판
⇒ 두 기법을 곱해서 더 선명하고 정밀한 히트맵 생성
(1). 실제 의료 적용 사례
1. 뇌졸중 예측 (CT 혈관조영술)
*오토인코더로 사전 학습 후 Grad-CAM으로 시각화
→ 전문가 주석 없이도 예측 성능 대폭 향상
? 오토인코더
입력 데이터를 압축(인코딩)하여 핵심 특징을 추출한 뒤,
다시 원본 데이터로 복원(디코딩)하도록 학습하는 비지도 학습 인공신경망
2. 결정성 경화증 분류
CNN으로 이형성증 IIb형(자궁경부) vs 피질 결절 분류(뇌 질환)
Guided Grad-CAM으로 형태학적 특징 시각화
→ 웹 기반 딥러닝 진단 앱으로 구현
3. 뇌종양 CAD 시스템
Grad-CAM으로 의사결정 과정을 시각화한 컴퓨터 지원 진단 시스템
→ 의사가 AI 판단을 신뢰하고 더 정확한 진단 가능
4. 뇌, 컴퓨터 상호작용 (MRI)
Xception 아키텍처 + 전이 학습 + SVM 분류
Grad-CAM으로 중요 특징의 공간적 위치를 히트맵으로 표시
→ 비정상 뇌 조직 식별 + 과적합 문제 완화
5. 뇌종양 분류 - Vision Transformer(VIT) 적용
VIT + Grad-CAM + LIME + SHAP 조합
성능 비교 :
- 기존 CNN : 83.37%
- VIT 모델 : 91.61%
⇒ 기존 CNN보다 약 8% 높은 정확도 달성
6. 림프절 전이 판단
Grad-CAM으로 조직학적 림프절 단면을 시각화
→ 원격 전이 조직 존재 여부 판단에 활용
{6}. Grad-CAM의 한계
| 한계 | 설명 |
| 노이즈 민감 | 입력이 조금만 바뀌어도 히트맵이 달라질 수 있음 |
| 일관성 부족 | 같은 이미지도 실행마다 결과가 다를 수 있음 |
| 국소적 설명만 만 가능 | 전체 데이터의 패턴, 관계는 설명 못함 |
(1). 보완
- 노이즈 민감, 일관성 부족 : Attention Mechanism = 노이즈 영향 적고, 일관된 결과
- 국소 설명만 가능 : SHAP = 전역적으로 특징 중요도 정량화
{7}. CAM 계열 기법 정리
- CAM : 망원경 - 정해진 방향만 볼 수 있음
→ 전역 평균 폴링 필요, 특정 CNN에만 적용
- Grad-CAM : 손전등 - 어디든 비출 수 있음
→ 어떤 CNN에도 적용 가능, 사후 로컬 설명
- Guided Grad-CAM : 현미경 - 더 정밀하게 들여다봄
→ Grad-CAM + 가이드 역전파 = 더 선형만 히트맨
{8}. LRP (Layer-wise Relevance Propagation, 계층별 관련성 전파 )
LRP는 비유하면 영수증 정산이다.
예를 들면,
- 식당에서 계산할 때 총금액을 각 메뉴별로 얼마인지 쪼개 놓은 것
AI의 최종 판단을 각 픽셀이 얼마나 기여했는지, 레이어를 거슬러 올라가며 쪼개서 분배한다.
즉, 최종 결과에 대한 기여도를 레이어별로 역으로 쪼개 다시 내려가는 기법이다.
(1). 핵심 원리
출력 (분류 점수)
↓ 역방향으로 관련성 점수 전파
레이어 N
↓
레이어 N-1
↓
...
입력 픽셀 (각 픽셀에 관련성 점수 할당)전파된 관련성 점수의 합 = 해당 점수를 만든 뉴런의 전체 점수
점수가 사라지거나 추가되지 않고 정확히 분배됨
(2). 실제 의료 적용 사례
1. 3가지 암 분류 (피부암, 유방암, 폐암)
- LRP로 픽셀 단위 히트맵 생성
→ AI의 판단 근거가 전문가의 임상 지식과 높은 일치도 보임
반대로 히트맵이 의학적으로 말이 안 되는 부위를 강조하면
데이터셋에 편향이 있다는 신호로 활용 가능하다.
(3). 정리 Grad-CAM vs LRP
| 구분 | Grad-CAM | LRP |
| 비유 | 손전등 | 영수증 정산 |
| 방식 | gradient로 중요 영역 강조 | 기여도를 레이어별로 분배 |
| 설명 단위 | 영역 | 픽셀 |
| 정밀도 | 중간 | 높음 |
| 편향 탐지 | 어려움 | 가능 |
{9}. Deep SHAP
(1). Deep SHAP이란
Deep SHAP을 비유하면 팀 프로젝트 기여도 평가이다.
팀 프로젝트 결과물이 나왔을 때
A = 40%, B = 35%, C = 25% 기여하는 것처럼
각 팀원의 기여도를 공정하게 나누는 것이다.
Deep SHAP도 AI의 최종 예측에 대해서
A 픽셀이 30, B 픽셀이 20%, C 픽셀이 50% 기여했다 처럼
각 특징의 기여도를 정량화하는 기법이다.
(2). 어떻게 만들어지나?
1. 기존 SHAP 문제점
모든 특징조합을 다 계산해야 함
계산 비용이 너무 많이 듦
2. 해결책 : Deep SHAP
Deep SHAP = *DeepLIFT + Shapley 값
- CNN에 맞게 계산을 효율적으로 근사화
- 빠르고 정확한 기여도 계산 가능
? DeepLIFT란
기준값(정상 이미지) 대비 입력값의 변화에 얼마나 영향을 미쳤는지 계산하는 기법
(3). 실제 의료 적용 사례
1. 폐암 탐지 - DeepXplainer
CNN + XGBoost 하이브리드 모델에 SHAP 적용
- 정확도 : 97.43%
- 민감도 : 98.71%
- *F1 점수 : 98.08%
- 국소적(개별 환자) + 전역적(전체 패턴) 설명 동시 제공
? F1 점수란
정밀도와 재현율을 조화평균하여 분류 모델의 성능을 종합 저긍로 평가하는 지표
2. 결핵 탐지 (흉부 X-ray)
분할 네트워크로 관심 영역만 추출 후 CNN 분류
XAI로 결핵 감열 폐 영역 강조
- 정확도 : 99.1%
- ROC : 99.9%
원본 이미지보다 분할된 이미지가 더 높은 성능 보임
3. 피부암 분류 - Skin-CAD
4개의 CNN + PCA + LIME 조합
- 피부암 악성/양성 데이터셋 : 97.2%
- HAM10000 데이터셋 : 96.5%
4. 피부암 - Grad-CAM vs Kerner SHAP 비교
30개의 모델을 만들어서 두 기법의 신뢰성 비교
핵심 발견 :
모델 정확도가 높다고 설명 가능성도 높은 건 아니다.
⇒ 정확도!= 설명 가능성
5. 폐 CT -GAX 프레임워크
의료 가이드라인 + SHAP 기반 설명을 결합
- AI판단이 실제 임상 기준에 맞는지 검증 가능
- 데이터 편향도 함께 발견
(4). 정리
| 구분 | LRP | Deep SHAP |
| 비유 | 영수증 정산 | 팀 기여도 평가 |
| 기반 이론 | 보존 법칙 | 게임 이론 (Shapley 값) |
| 설명 범위 | 픽셀 단위 | 특정 단위 |
| 전역 설명 | X | O |
| 계산 비용 | 중간 | 높음 |
{10}. Perturbation 기반 접근 방식
(1). Perturbation(섭동)이란
안정적인 계(Sytem)가 외부의 미세한 영향으로 인해 원래 상태에서 조금 벗어나는 복잡한 움직임이나 현상을 말한다.
예를 들면,
그림의 특정 부분을 지웠을 때
- AI의 판단이 바뀌면 : 그 부분이 중요한 것
- AI의 판단이 안 바뀌면 : 그 부분은 중요하지 않은 것
즉, 일부러 이미지를 건드려서 어느 부분이 중요한지 역으로 파악하는 방식이다.
(2). 세부 기법
1. Occlusion Sensitivity(가림 민감도)
이 기법은 눈 가리기 게임이다.
예를 들면
이미지 특정 부분을 가린다. 이후,
- AI 판단이 크게 흔들리면 : 그 부분이 핵심
- AI 판단이 그대로면 : 그 부분은 중요하지 않음
실제 적용 :
-1. 알츠하이머, 자폐증 (뇌 MRI)
3D-CNN + 유전 알고리즘으로 뇌에서 질병과 관련된 행심 영역 추출
- 알츠하이머(ADNI) : 6~65개 핵심 뇌 영역추출
- 자폐증(ABIDE) : 15~75개 핵심 뇌 영역 추출
-2. 황반변성, 당뇨병성 환반부종 (안저 이미지)
- 가림 테스트로 AI가 주목하는 영역 파악
⇒ 의료 전문가에게 판단 근거 전달 가능
2. LIME (로컬 해석 가능모델)
이 기법은 복잡한 요리를 단순한 레시피로 설명하는 것이다.
복잡한 AI 모델(CNN)을 단순한 모델(선형 모델)로 근사해서
"이 부분 때문에 이런 판단을 내렸어"를 설명
핵심 원리 :
- 입력을 조금씩 바꿔가면서
- 출력이 어떻게 변하는지 관찰
- 변화 패턴으로 중요 특징 파악
실제 적용 :
-1. 소아 흉부 X-ray (폐렴 진단)
- LIME으로 AI가 주목한 폐 영역 시각화
⇒ 의사의 임사 결정 지원
-2. 위내시경 (출혈 부위 탐지)
- LIME으로 출혈 의미 부위 강조
3. 의미 있는 교란
이 기법은 단순히 지우는 게 아니라 자연스럽게 바꾸는 것이다.
기존 방식 :
- 이미지 일부를 검게 가림
- 의료 영상에선 부자연스러움
개선 방식 :
- 병변 부위를 정상 조직처럼 자연스럽게 대체
- 더 현실적이고 의미 있는 설명 가능
교란 방법 3가지 :
- 상수 값 대체 : 해당 부분을 고정된 값으로 채움
- 노이즈 추가 : 해당 부분에 랜덤 노이즈 추가
- 흐름 처리 : 해당 부분을 흐리게 만듦
더 발전된 방법 :
-1. VAE(Variational Auto-Encoder) 교란 :
단순히 가리는 게 아니라 병변 부위를 정상 조직으로 자연스럽게 대체
- 적용 : 뇌 MRI, 안구 OCT 영상
- 결과 : 흐림, 상수값 교란보다 병변 위치를 더 정확하게 파악
-2. 인페인팅(Inpainting) 방식 :
VAE와 유사하게 병변을 정상 조직으로 대체
- 결핵, 유방암 흉부 X-ray에서
- 역전파, Grad-CAM보다 더 정확한 위치 파악
4. 예측 차이 분석 (Prediction Difference Analysis)
{11}. 다중 인스턴스 학습(MIL) 기반 접근 방식 - 과일 바구니 검사
Multiple Instance Learning의 약자이다.
MIL는 이미지 전체에 대한 라벨만 있어도, AI가 스스로 어느 패치가 중요한지 찾아내는 학습 방식이다.
예를 들면
바구니 = 이미지 전체
과일(Instance) = 이미지에서 잘라낸 패치(조각)
검사관이 바구니를 보고
"이 바구니엔 상한 과일이 있다" (바구니 레이블 O)
But 어떤 과일이 상했는지 모름 (개별 레이블 X)
그래도 학습하다 보면
"상한 바구니엔 이런 과일이 자주 있더라"를 스스로 파악하게 됨
즉, 전체에 대한 레이블만 있어도, 어느 부분이 중요한지 스스로 찾아내는 학습 방식이다.
더 쉽게 말해서
"이 이미지에 종양이 있다 / 없다"처럼 이미지 단위 라벨만 있어도
AI가 스스로 그 이미지 안에서 "어떤 패치(Instance)가 암으로 의심되는지" 찾는다.
(1). 일반 학습 vs MIL 비교
1. 일반 학습 :
"이 이미지의 이 부분이 종양이야" (부위까지 표시 필요)
→ 전문가가 일일이 레이블링 해야 하기 때문에 시간, 비용이 엄청남
2. MIL :
"이 이미지에 종양이 있어" (이미지 단위 레이블)
→ 어느 부분인지 몰라도 되기 때문에 레이블링 부담이 대폭 감소한다.
→ AI가 스스로 종양 부위를 찾아냄
(2). 실제 의료 적용 사례
1. 두 개 내 출혈 탐지 (CT 탐지)
스캔 전체 레이블만 사용하기 때문에 슬라이스별 중요 신호 자동 탐지
- 레이블링 시간 : 10시간 미만
- ROC-AUC : 0.91
⇒ 대규모 수동 레이블링 모델과 유사한 성능
핵심은 적은 노력으로 전문가 수준의 성능을 발휘함
2. 흉부 X-ray - 중요 소견 국소화
이미지를 패치로 잘라서 각각 예측값 부여하여
원본 이미지에 중첩해서 "AI가 어디를 보고 판단했는지" 시각화
3. 당뇨병성 망막병증 (안저 영상)
패치 기반으로 각 망막병증 등급별 시각적 설명 맵 생성
⇒ 등급마다 어떤 부위가 중요한지 시각화
(3). 정리
| 구분 | Perturbation | MIL |
| 비유 | 지우개 테스트 | 과일 바구니 |
| 레이블 | 픽셀, 영역 단위 필요 | 이미지 단위 레이블 |
| 레이블링 비용 | 높음 | 낮음 |
| 설명 방식 | 중요 픽셀 강조 | 중요 패치 식별 |
| 적합한 상황 | 정밀한 설명이 필요할 때 | 레이블리 부족할 때 |
[4.2] Attention Mechanism - 스포트 라이트
공연장에서 스포트라이트가
중요한 인물에게만 집중적으로 비추듯
Attention Mechanism은
이미지에서 중요한 부위에 가중치를 높게 부여한다.
"여기가 핵심이야"를 모델 스스로 표시하는 것이다.
실제 적용 :
- CT 스캔 : 폐 이상 관련 특정 영역 자동 가조
- MRI : 뇌종양 의심 영역 자동 강조
AI가 임상적으로 관련 없는 영역에 스포트라이트를 비출 수도 있다. 반드시 의사가 검증해야 한다.
[4.3]. Global Explanation - 지도 vs 골목 안내
{1}. 전역 설명(지도)
- 도시 전체 구조를 한눈에 파악
- "이 AI는 전반적으로 이런 패턴으로 판단해"
{2}. 지역 설명(골목 안내)
- 특정 골목의 세부 경로 안내
- "이 환자를 왜 이렇게 진단했어"
{3}. 전역 모델이 잘하는 것 :
- 해부학적 영역과 질병 심각도 간의 상관관계 파악
- 전체 데이터셋의 패턴, 트렌드 발견
- 모델이 전반적으로 어떻게 작동하는지 이해
{4}. 못하는 것 :
- 개별 환자 예측을 세밀하게 설명하기 어려움
즉, Global Explanation + Local Explanation을 같이 써야 완전한 그림이 나온다.
[4.4]. Counterfactual Explanation - 만약에
"만약 종양 크기가 더 작았다면 결과가 달랐을까?"
현재 : 나이 65세 + 흡연력 30년 + 음영 크기 3cm
→ AI 판단 : 악성 가능성 높음
가상 : 나이 65세 + 흡연력 0년 + 음영 크기 3cm
→ AI 판단 : 양성 가능성 높음
⇒ "흡연력이 핵심 변수구나!"를 역으로 파악
이게 의료에서 유용한 이유는 :
- 임상의 : " 어떤 특징이 이 진단에 가장 큰 영향을 줬나? "
- AI : " 음영 경계가 불규칙하지 않았다면 양성으로 판단했을 겁니다 "
⇒ 임상의가 AI 판단의 핵심 근거를 이해하고, 추가 검사 방향을 잡는 데 활용 가능
[4.5]. Hybrid XAI - 도시락 세트
밥만 있으면 부족하고
반찬만 있어도 부족하듯
Grad-CAM(시각) + 텍스트 설명 + SHAP(수치)
⇒ 세 가지를 함께 담아야 완전한 설명이 됨
하이브리드가 필요한 상황들은
희귀 질환 진단이다. 희귀 질환은
- 시각적 근거(Grad-CAM)만으론 부족
- 텍스트 설명 + 수치 근거까지 함께 제공해야 함
⇒ 그래야지 의사가 납득하고 신뢰할 수 있음
여러 기법을 동시에 돌리면 계산 비용이 급격히 증가한다. 실시간 진단이 필요한 상황에서는 부담이 될 수 있다.
[4.6]. Text Description - 말로 설명하는 XAI
위에서 설명한 XAI는 대부분 시각화 방식이었다. 텍스트 설명은 여기서 한 발 더 나아가 "글로 설명"해주는 방식이다.
{1}. Image Caption - 사진에 설명 붙이기
인스타그램에 사진을 올릴 때
캡션으로 "오늘 먹은 파스타, 크림소스가 진해서 맛있었음"
처럼 사진을 글로 설명하는 것
AI가 의료 영상을 보고
"오른쪽 폐 하단에 음영 패턴이 관찰됨"
을 자동으로 생성해 주는 기법이다.
실제 적용 :
(1). 흉부 X-ray 자동 보고서 생성
병원 아카이빙 시스템의 방사선 보고서를 학습
- AI가 X-ray를 보고 자동으로 정리된 보고서 출력
- 임상 의사결정 시스템에 직접 활용
성능 비교 :
기존 살리언시 맵보다 이미지 캡션 방식이 실제 테스트에서 더 우수한 성능을 보임
{2}. Image caption + Combine Visual Description - 뉴스 화면 + 자막
뉴스에서 앵커가 말로 설명하면서
동시에 화면에 관련 영상을 보여주듯
AI가 텍스트 설명을 생성하면서
동시에 해당 부위를 이미지에서 강조해 줌
구체적인 연구들 :
(1). 이중 어텐션 시스템
입력 1 :이미지를 인코더로 분석하고,
입력 2 : "이 부위에 암세포가 있습니다" 텍스트를 LSTM으로 분석한다.
두 가지를 동시에 보면서
"텍스트에서 말하는 '암세포 부위'가 이미지에서 어디에 해당하는지"를 찾아냄
결과 : 이미지에서 해당 부위를 강조한 어텐션 맵 생성
(2). 멀티태스크 학습 프레임워크
- 태그 예측 + 설명 생성을 동시에 수행
- 시각 정보 + 의미 정보를 함께 분석
⇒ 이상 위치를 정확히 찾고 설명까지 자동 생성
(3). 방사선 영상 위치 레이블 자동 추출
- 텍스트 보고서에서 위치 정보를 자동 추출
- 해당 위치를 이미지에 자동 표시
*Bi-LSTM + *DenseNet-121 조합으로 구현
? Bi-LSTM이란
텍스트를 앞에서 뒤로, 뒤에서 앞으로 동시에 읽는 모델
⇒ 문맥을 더 잘 이해하기 위해
? DenseNet-121
이미지를 분석하는 CNN 모델 중 하나
⇒ 121개의 레이어로 구성된 깊은 신경망
둘이 합치면 :
- Bi-LSTM : 텍스트 보고서에서 위치 정보 추출
- DenseNet-121 : 이미지에서 해당 위치 찾기
즉, "보고서에 적힌 위치"와 "이미지의 실제 위치"를
자동으로 연결해 주는 시스템이다.
(4). 유방 조영술 캡션 생성
- 이미지 캡션 + 시각적 설명 결합
생성된 텍스트가 실제 유방 조영술 보고서 언어와
일치하도록 제약 조건 추가함.
{3}. TCAV 개념 활성화 벡터 테스트 - 어느 개념이 중요해?
Testing with Concept Activation Vectors의 약자로
"AI가 얼룩말이라고 판단한 건, 줄무늬라는 개념을 얼마나 중요하게 봤기 때문인가?"를 숫자로 측정하는 기술이다.
기존 XAI는 "어느 픽셀이 중요해?"를 물었다면 TCAV는 "어느 개념이 중요해?"를 묻는다.
- 픽셀 기반 질문 (기존) : "이 이미지의 어느 부분이 중요해?"
- 개념 기반 질문 (TCAV) : "악성 종양 판단에 '돌출된 종괴'라는 개념이 얼마나 영향을 미쳤어?"
예시 :
의료 AI에게 물어보면
- "돌출된 종괴 개념이 악성 판단에 얼마나 중요해?" ⇒ 매우 중요
- "핵 면적 개념이 정상/악성 구분에 중요해?" ⇒ 그렇지 않음
회귀 개념 백터를 발전시켜서
- 기존 TCAV : "이 개념이 있어? 없어?" ⇒ 이진 판단
- 회귀 개념 벡터 : "이 개념이 얼마나 있어?" ⇒ 연속 값 측정
예시 :
- 기존 : "종양이 있다 / 없다"
- 개선 : "종양 크기가 얼마나 크다" ⇒ 더 세밀한 분석 가능
실제 적용 :
- 심장 MRI : 박출률 같은 임상 지표를 TCAV로 검증
- 유방 조직병리학 : "대비"/"핵 면적" 개념이 각각 얼마나 중요한지 정량화
{4}. 정리
| 기법 | 비유 | 설명 방식 | 특징 |
| 이미지 캡션 | 사진에 설명 달기 | 이미지에서 텍스트 자동 생성 | 보고서 자동화에 유용 |
| 캡션 + 시각화 | 뉴스 화면 + 자막 | 이미지 + 텍스트 동시 설명 | 가장 완전한 설명 |
| TCAV | 개념 중요도 측정 | "이 개념이 얼마나 중요해?" | 임상 개념과 연결 가능 |
히트맵은 의사한테 익숙하지만 환자는 ㅣ해하기 어렵다. 텍스트 설명은 의사뿐 아니라 환자도 이해할 수 있는 가장 접근성 높은 XAI 방식이다.
[4.7]. 예시 기반 설명 - 의사의 경험적 판단
베테랑 의사가 환자의 MRI 사진을 보면서
"이거 작년에 봤던 그 환자랑 비슷하네 그 환자가 악성이었으니 이것도 의심해 봐야겠다"
AI도 똑같이
"이 이미지는 학습 데이터의 저 이미지와 비슷해 그러니까 이렇게 판단했어"
라고 설명하는 방식이다.
{1}. 트리플렛 네트워크 - 얼마나 비슷한가
세 장의 이미지를 동시에 비교해서 "비슷한 것끼리는 가깝게, 다른 것끼리는 멀게" 배치하도록 학습하는 네트워크이다.
세 장의 사진을 동시에 비교해서
"A와 B는 비슷하고, A와 C는 달라"를 학습하는 방식이다.
- 닮은 것끼리 : 잠재 공간에서 가까이 배치
- 다른 것끼리 : 잠재 공간에서 멀리 배치
세 장의 이미지 입력은 항상 아래 조합이다 :
- Anchor : 기준 샘플 (예 : 내 얼굴 사진)
- Positive : Hnchor와 같은 클래스 (예 : 나와 얼굴이 비슷한 사람 사진)
- Negative : Anchor와 다른 클래스 (예 : 나와 얼굴이 완전 다른 사람 사진)
트리플렛 네트워크의 목표는 하나다.
- Anchor와 Positive의 거리는 줄이고
- Anchor와 Negative 거리는 늘리는 것이다.
실제 적용 :
(1). 병변 유사도 검색 (전신 CT)
32,000개 병변 학습 시 3가지 기준으로 비교
병변 크기 / 해부학적 위치 / 신체 내 좌표
간 병변과 폐 병변 자동 구분
"이 병변은 저 병변과 비슷합니다" 형태로 설명
(2). 흑색종 피부과 사진
트리플렛 + CAM 전역 평균 폴링 결합
예시 기반 설명 + 검색 결과 활성화 맵 + 쿼리 활성화 맵
세 가지를 동시에 제공함
{2}. 영향 함수 - 이 데이터가 없었다면?
학습 데이터 하나를 빼거나 바꿨을 때
AI의 판단이 얼마나 달라지는지 측정하는 것이다.
판단이 크게 달라지면
그 데이터가 AI 결정에 큰 영향을 준 것을 의미한다.
실제 적용 :
(1). 간 병변 MRI 분석
어떤 방사선학적 특징이 어떤 병변 범주와 연관되는지 규명
발견 예시 :
"얇은 벽을 가진 종괴"는 "양성 낭종" 진단과 가장 강하게 연결되는 특징으로 나타남
AI가 왜 이 진단을 내렸는지 근거 제시
의사가 AI 출력을 신뢰할 수 있게 됨
{3}. 프로토타입 - 교과서에 있는 대표 예시
교과서에서 "자동차"를 설명할 때
전형적인 자동차 사진을 보여주듯
AI도 각 클래스의 "대표 이미지(프로토타입)"를 골라서
"이 환자 이미지가 이 대표 이미지와 비슷해서 이렇게 진단했습니다"라고 설명하는 것이다.
사후 추측이 아닌 실제 신경망 계산과정 자체에서 설명이 나옴
이것은 더 정확하고 신뢰할 수 있는 설명이 될 수 있다.
실제 적용 :
(1). 조직학 이미지 암 판별
AI가 특정 영역을 "암"으로 판단했을 때
"이 부분이 학습 데이터의 이 대표 암 이미지와 이만큼 유사해서 그렇게 판단했습니다"
라고 근거를 제시했다.
{4}. 잠재 공간의 예시 - AI의 내부 분류 서랍
사람이 머릿속에서 개념을 정리할 때
"크다/작다", "둥글다/뾰족하다" 같은 특성으로 분류해서 저장하듯
AI도 잠재 공간이라는 내부 서랍에 이미지의 특성을 압축해서 저장한다.
발전된 두 가지 방법 :
(1). 적대적 VAE
기존 VAE보다 더 정확하게
사람이 이해할 수 있는 특성을 학습한다.
예) :
병변 크기 / 병변 모양 / 피부색
각각을 분리해서 더 정확히 재현 가능함
(2). 캡슐 네트워크
기존 CNN : 픽셀 정보만 저장
캡슐 네트워크 : 크기, 두께, 왜곡 같이 "사람이 이해할 수 있는 속성"을 저장
실제 적용 - 폐암 진단 :
구형도 / 엽상 구조 / 질감
시각적 특징을 함께 예측
"이 결절이 왜 악성인지"를 특성으로 설명
{5}. 정리
| 기법 | 비유 | 설명 방식 | 적용 |
| 트리플렛 네트워크 | 닮은꼴 찾기 | 유사 이미지 비교 | 병변 유사도 검색 |
| 영향 함수 | 데이터 제거 실험 | 학습 데이터 영향도 측정 | 간 병변 MRI |
| 프로토타입 | 교과성 대표 예시 | 대표 이미지와 비교 | 조직학 암 판별 |
| 잠재 공간 | 내부 분류서랍 | AI 내부 특성 해석 | 폐암, 피부 병변 |
[4.8]. 멀티모달 XAI - 퍼즐 맞추기
하나의 퍼즐 조각만으론 그림을 알 수 없듯
의료 영상만으론 부족할 수 있다.
영상 + 임상 기록 + 유전자 정보 + 환자 이력
모든 조각을 합쳐야 완전한 그림이 나온다.
실제 예시 :
암 진단에서 MRI 영상만 보는 게 아니라
유전적 표지자 + 환자 이력 + 영상 데이터
세 가지를 동시에 분석해서 더 정확하고 포괄적인 설명을 제공한다.
단점은 데이터 종류가 많아질수록 컴퓨팅 자원이 엄청나게 필요하다.
[4.9] 신흥 기술들이 XAI를 어떻게 바꾸고 있나?
XAI가 직면한 3가지 핵심 문제 :
- 데이터 부족
- 계산 비용
- 실제 임상 현장 적응의 어려움
아래 신기술들이 이 문제들을 하나씩 해결하고 있다.
{1}. 생성형 AI(GAN, 확산 모델) - 가짜 환자 데이터 공장
희귀 질환은 실제 데이터가 너무 적다 그렇기 때문에
GAN으로 고품질 합성 의료 영상 생성
실제 환자 데이터 없이도 학습 가능
⇒ 개인정보 보호 + 데이터 부족 동시 해결
추가로 반사실적 시각화 생성을 하면
"이 폐에 음영이 없었다면 AI가 정상으로 판단했을까?" 같은 가상 이미지를
실제로 만들어서 보여줄 수 있다.
{2}. 멀티모달 모델 - 다학제 진료 팀
내과 + 영상의학과 + 유전상담사가 함께 진료하듯
영상 데이터 + 유전체 프로파일 + 임상 기록
여러 전문 분야 데이터를 하나로 통합하는 것이다.
이 기법은 암 진단에서 특히 유망한 결과를 보이고 있다.
{3}. Foundation Mode(기초 모델) - 만능 의대생
의대에서 기초를 폭넓게 배운 후
각 과에서 전문의 수련을 받듯
대규모 데이터로 사전 학습 후
특정 질환에 맞게 미세 조정(Fine-Tuning)을 진행
- 적은 레이블 데이터로도 다양한 영상에서 작동
- 여러 임상 워크플로우에 표준화된 솔루션 제공
{4}. 고급 컴퓨팅 프레임워크, 연합 학습 - 데이터는 각 병원에, 지식만 공유
A병원 + B병원 + C병원이 협력할 때
환자 데이터를 직접 주고받지 않고
각 병원에서 학습한 결과(모델 가중치)만 공유하는 것이다.
그러면
GDPR, HIPADD 같은 개인정보 규정을 준수할 수 있고
다양한 데이터로 강력한 모델 개발이 가능하다.
(1). Edge Computing - 현장 즉성 판독
서버에 데이터를 보내고 기다리는 게 아니라
의료기기 자체에서 바로 AI 분석 실행
- 응급실에서 즉각적인 XAI 결과 제공
- 휴대용 초음파, 웨어러블 기기에 탑재 가능
(2). BlockChain - 변조 불가능한 의료 기록부
한 번 기록되면 절대 수정할 수 없는 블록체인 장부처럼
XAI가 생성한 설명의 출처와 과정을 투명하게 기록, 검증
- AI 판단에 대한 신뢰도 향상
- 기관 간 안전한 데이터 공유
{5}. AI 기술과의 융합
(1). IoMT (의료 사물 인터넷) - 24시간 AI 주치의
심전도 모니터, 영상 기기 등 의료기기가
실시간으로 XAI와 연결
환자 상태를 24시간 모니터링
이상 감지 시 즉각적인 설명과 함께 알림
심장 사건 조기 진단에 특히 유용
(2). 강화 학습 - 피드백으로 성장하는 AI
의사가 "이 설명은 도움이 돼 / 안 돼"라고 피드백하면
AI가 점점 더 유용한 설명을 학습
즉, ICU 같은 동적 환경에서 실시간으로 최적화된 설명을 제공해 준다.
(3). 신경, 기호적 AI - 직관 + 논리의 결합
신경망(직관) : "이 이미지는 암 같아"
기호 시스템(논리) : "왜냐하면 임상 가이드라인 기준 모양이 불규칙하고, 폐에 음영이 보이기 때문에"
⇒ 데이터 기반 예측 + 규칙 기반 설명 동시 제공
(4). NLP - AI 통역사
히트맵이나 숫자로 된 XAI 결과를
자연스러운 문장으로 번역
"이 부위의 음영 패턴이 폐렴 가능성을
높이는 주요 근거입니다."
- 의사뿐 아니라 환자도 이해 가능
- 방사선 보고서, 전자 건강기록과 자동 연동
{6}. 정리
| 기술 | 비유 | 해결하는 문제 |
| 생성형 AI | 데이터 공장 | 데이터 부족 |
| 멀티모달 | 다학제 진료팀 | 단일 데이터 한계 |
| 기초 모델 | 만능 의대생 | 범용성 부족 |
| 연합 학습 | 지식만 공유 | 개인정보 보호 |
| 엣지 컴퓨팅 | 현장 즉석 판독 | 실시간 처리 |
| 기술 | 비유 | 해결하는 문제 |
| 블록체인 | 변조 불가 기록부 | 신뢰성, 투명성 |
| IoMT | 24시간 AI 주치의 | 실시간 모니터링 |
| 강화 학습 | 피드백 성장 | 설명 최적화 |
| 신경, 신호적 AI | 직관 + 논리 | 논리적 설명 부족 |
| NLP | AI 통역사 | 비전문가 이해 |
[4.10]. XAI의 한계와 상충 관계 - 모든 도구엔 단점이 있다.
XAI 기법들이 아무리 발전해도 각각 한계가 있다. 현재 주요 기법들의 문제점을 보면
{1}. Saliency Map (Grad-CAM 등)
Grad-CAM은 위에서 손전등에 비유를 했다.
손전등이 엉뚱한 곳을 비출 수 있다.
- 실제 병변이 아닌 관련 없는 영역을 강조할 수 있다.
- 의사가 잘못된 부위를 보고 오판할 위험이 있다.
{2}. 예시 기반 설명
위에서 의사의 경험적 판단으로 비유를 했다.
비슷한 과거 환자 사례를 전부 뒤져봐야 하는데
환자가 많아질수록 찾는 데 시간이 엄청 걸림
- 계산 비용이 매우 높음
- 데이터가 많아질수록 더 느려짐
{3}. 반사실적 설명
"만약에"라는 비유를 했다.
"음영이 없었더라면?" 같은
현실적이고 의미 잇는 가상 시나리오를 만드는 것이
의료 영상에선 생각보다 훨씬 어렵다.
{4}. 결론
- 해석 가능성이 높으면 계산 비용도 높아진다.
- 신뢰성이 높으면 속도는 떨어진다.
해석 가능성, 신뢰성, 속도, 낮은 비용을 동시에 완벽히 만족하는 XAI 기법은 아직 없다. 상황에 따라 적절히 선택하고 조합하는 게 현재로선 최성이다.
[4.11]. XAI의 윤리적 고려 사항
기술만큼 원칙도 중요하다
XAI가 아무리 성능이 좋아도 윤리적으로 잘못 쓰이면 오히려 해가 될 수 있다.
3가지 핵심 윤리 원칙이 있는데 아래와 같다.
{1}. Fairness(공정성) - 모든 학생에게 공평한 시험
시험 문제가 특정 학생에게만 유리하면 불공평하듯
XAI 모델이 특정 인종, 성별, 연령대 데이터로만 학습되면
그 집단에게만 유리한 진단을 내릴 수 있다.
예) :
백인 환자 데이터 위주로 학습된 피부암 AI
⇒ 유색인종 환자에서 진단 정확도 대폭 하락
해결책 :
- 다양한 인구 집단이 포함된 데이터셋 구성
- 공정성을 고려한 알고리즘 사용
- 모든 집단에서 성능 검증
{2}. Accountability(책임성) - 블랙박스 없는 의료 기록
자동차 사고가 나면 블랙박스로
"왜 사고가 났는지" 추적하듯
AI가 잘못된 진단을 내렸을 때
"왜 그런 판단을 했는지" 추적이 가능해야 한다.
실제 방법 :
- SHAP and Grad-CAM : 예측 근거를 시각화, 수치화
- 결정 로그 : AI가 내린 판단 기록 보관
- 모델 버전 관리 : 어떤 버전이 어떤 판단을 했는지 추적
문제 발생 시 감사 가능
의료, 법적 책임 명확화
{3}. 데이터 개인정보 보호 - 환자 정보는 금고 안에
병원 기록은 절대 외부에 함부로 나가면 안 되듯
XAI 학습에 환자 데이터를 쓸 때도 개인정보 보호가 최우선이다.
관련 법규 :
- GDPR : 유럽 개인정보 보호법
- HIPAA : 미국 의료정보 보호법
- AI기본법 : 한국 AI 규제 기본법
기술적 해결책 :
연합 학습 :
환자 데이터는 각 병원에 두고, 학습 결과 9 지식)만 공유
차분 개인정보 보호 (Differential Privacy) :
데이터에 의도적 노이즈를 추가해서 개인정보 식별을 불가능하게 만들면서도
통계적 패턴은 유지
{4}. 정리
| 원칙 | 비유 | 핵심 내용 | 해결 방법 |
| 공정성 | 공평한 시험 | 모든 환자에게 동등한 성능 | 다양한 데이터셋 구성 |
| 책임성 | 블랙박스 추적 | AI 판단 근거 감사 가능 | SHAP and Grad-CAM, 결정 로그 |
| 개인정보 보호 | 환자 정보 금고 | 민감한 데이터 보호 | 연합 학습, 차분 프라이버시 |
출처 :
https://super-son.tistory.com/44
[EDA] 데이터 시각화 - 히트맵 (Heatmap)
히트맵이란?히트맵(Heatmap)은 데이터 값의 크기나 빈도에 따라 색상이 변하며, 이를 통해 데이터의 패턴, 분포 및 관계를 쉽게 파악할 수 있으며, 주로 상관 행렬이나 공간 데이터
super-son.tistory.com
https://bommbom.tistory.com/entry/Xception-구조-및-특징
Xception 구조 및 특징
Inception 모델에 이어 Xception 모델을 알아보겠습니다. 이 모델도 이미지 분류 작업을 위해 설계된 CNN(컨볼루션 신경망) 아키텍처입니다. Keras 딥러닝 라이브러리 창시자인 François Chollet가 2017년에
bommbom.tistory.com
https://velog.io/@ghkddhf123/tcav-정리
TCAV, ACE 정리
신경망 계층의 활성화 공간에서 개념을 일반화하는 수치 표현이다. C는 concept, l은 layer이다. 해당 활성화 공간에 줄무늬 개념 데이터와 줄무늬가 아닌 랜덤한 데이터가 있고 이를 학습을 통해 cla
velog.io
'AI > 논문 & 연구자료' 카테고리의 다른 글
| Refining explainability in chest x-ray diagnostics with lesion-aware hybrid transformer and local similarity of integrated re-normalized attention map (0) | 2026.05.24 |
|---|---|
| Xception (0) | 2026.05.16 |
| 딥러닝을 활용한 의료 영상 시스템을 위한 설명 가능한 인공지능 : 종합적인 검토 2 (1) | 2026.04.25 |
| 생성형 AI의 위협 (0) | 2025.12.09 |