[0]. SHAP (Shapley Additive Explanations)란?
게임 이론의 샤플리 값을 활용한 기법이다.
머신러닝 모델의 예측 결과를 각 피처(특징)의 기여도로 분해하여 설명하는 XAI 기법이다.
[1]. SHAP이 필요한 이유
예를 들어
모델이 "악성 종양, 확률 98%"라고 했을 때
- 왜 그 결론인가?
- 어떤 요소가 결정적이었나?
- 틀렸을 때 어디서 잘못됐나?"
이걸 답하는 것이 XAI, 그중 Feature Attribution 계열의 대표가 SHAP이다.
{1}. Feature Attribution이란?
예측값 = 기준값 + 피처1 기여 + 피처 2 기여 + ... + 피처 n 기여
즉, 각 피처가 예측에 얼마나, 어느 방향으로 기여했는지 수치로 분해하는 것이다.
근데 각 피처의 기여도를 어떻게 측정해야 공정할까?
{2}. 공정한 기여도란?
단순한 접근의 문제이다.
(1). 방법 1 : 피처 하나씩 제거하고 예측 변화 측정
예를 들어 요리사가 "이 재료가 맛에 얼마나 기여했나?"를 알려고,
재료를 하나씩 빼서 맛을 비교하는 것이다.
- f(소금, 설탕, 후추) = 0.82
- f(설탕, 후추) = 0.61 ⇒ 소금 기여 = +0.21
- f(소금, 후추) = 0.74 ⇒ 설탕 기여 = +0.08
- f(소금, 설탕) = 0.79 ⇒ 후추 기여 = +0.03
⇒ 합계 : 0.21 + 0.08 + 0.03 = 0.32
문제는 피처 간 상호작용이 존재하면, 어떤 피처를 먼저 제거하느냐에 따라 기여도가 달라진다.
- 소금 단독제거 기여도 = +0.21
- 설탕 먼저 빠진 상태에서 소금 제거 기여도 = +0.30 (다른 값)
즉, "진짜 기여도"가 없다. 순서 의존적이다.
그래서 모든 순서를 동등하게 고려하는 Shapley Value가 필요하다.
{3}. Shapley Value : 게임 이론에서의 해답
(1). 협력 게임 - Shapley 개념
기여도에 따른 공정한 분배 문제다. 3명(A, B, C)이 협력해서 300만원을 벌었다. 단순히 N분의 1로 나누면 불공평하다.
더 많이 기여한 사람이 더 가져가야 한다. 그렇다면 각자의 기여도를 어떻게 측정하는가?
- A = 60
- B = 80
- C = 50
- A, B = 180
- A, C 140
- B, C = 160
- A, B, C = 300
⇒ 단순히 단독 기여(60:80:50)로 나누면 불공정하다. 연합 효과를 고려해야 한다.
(2). Shapley의 해법 : 모든 순서에서의 평균 한계 기여도
위의 예시를 들고 와서
3명(A, B, C)이 협력해서 300만원을 벌었다.
각자에게 공정하게 얼마를 줘야 하는가?
예를 들어 팀 프로젝트에서
A, B, C 세명이 프리랜서로 함께 프로젝트를 수주했다
혼자서 하면
- A = 60만 원짜리 프로젝트밖에 못 받음
- B = 80만 원
- C = 50
협력하면
- A + B = 180 (시너지 발생)
- A + C = 140
- B + C = 160
다 같이 하면
- A + B + C = 300
단순히 “혼자일 때 기여도 비율(60:80:50)로 나누면 불공정하다.
⇒ A와 B가 만나면 시너지가 터지는데, 그 공을 누구에게?
(3). Shapley의 아이디어 : 합류 순서를 바꿔가며 실험해 보자
팀에 한 명씩 순서대로 합류한다고 가정하자
내가 합류하는 순간, 팀 수익이 얼마나 올랐는가?
그게 나의 "그 순서에서의 기여도"다.
이걸 가능한 모든 합류 순서에 대해 평균을 낸다.
3명이니까 합류 순서의 경우의 수 = 3! = 6가지
1. A의 Shapley Value
-1. A → B → C
- [빈 팀] → A 합류 → B 합류 → C 합류
- A가 들어올 때 팀에 아무도 없음
- ⇒ A 혼자서 벌 수 있는 돈 = 60만 원
-2. A → C → B
- [빈 팀] → A 합류 → C 합류 → B 합류
- 1과 같은 상황으로
- ⇒ A 기여도 = 60만 원
-3. B → A → C
- [빈 팀] → B 합류 → A 합류 → C 합류
- A가 들어올 때 팀에 B가 이미 있음
- B만 있을 때 수입 = 80만 원
- A + B가 함께일 때 수익 = 180
- A가 들어오면서 수익이 +100만 원이 오름
-4. C → A → B
- [빈 팀] → C 합류 → A 합류 → B 합류
- A가 들어올 때 팀에 C가 이미 있음
- C만 있을 때 수익 = 50만 원
- A+C가 함께일 때 수익 = 140만 원
- A가 들어오면서 수익이 90만 원이 오름
-5. B → C → A
- [빈 팀] → B 합류 → C 합류 → A 합류
- A가 들어올 때 팀에 B, C가 이미 다 있음
- B+C만 있을 때 수익 = 160만 원
- A+B+C 다 있으면 수익 = 300만 원
- A가 들어오면서 수익이 140만 원이 오름
-6. C → B → A
- [빈 팀] → C 합류 → B 합류 → A 합류
- A가 들어올 때 팀에 C, B 다 있음
- A 기여도 140만원
정리하면 A를 기준으로
- 1, 2의 경우 빈 팀에 혼자 들어가기 때문에 A의 기여도는 60이다.
- 3의 경우는 B가 있는 팀에 합류를 했기 때문에 기여도가 100이다
- 4의 경우는 C가 있는 팀에 합류해서 기여도는 90이고,
- 5, 6의 경우 B, C가 다 있는 팀에 합류해서 기여도가 140이다.
- 팀이 약할 때 들어가면 A의 기여도는 작게 측정
- 팀이 강할 때 들어가면 A의 기여도 크게 측정
그래서 6가지를 전부 평균내면
A = (60 + 60 + 100 + 90 + 140 + 140) / 6 하면 300만 원 중 A가 가져갈 돈은 98.3만 원이다.
같은 방식으로 B, C도 계산하면
B = 108.3만 원
C = 93.3만 원이다.
검증을 하면 98.3 + 108.3 + 93.3 = 300이 나온다.
유리한 순서(빈 팀)도, 불리한 순서(꽉 찬 팀)도 모두 동등하게 고려해서 평균을 냈기 때문에 공정하다.
[2]. SHAP 수식 완전 분해

SHAP의 수식은 위와 같다. 이걸 세 개의 덩어리로 쪼개면 아래와 같다.

- 덩어리 1 : 이 상황이 나올 확률 (가중치)
- 덩어리 2 : 이 상황에서 피처 i의 기여도
- 전체 수식 = “각 상황의 기여도 x 그 상황이 나올 확률”의 합계
즉, 가중 평균이다.
(1). 덩어리 분석
1. 덩어리 2
덩어리 2를 먼저 보면

- f(S U {i}) : 피처 i를 포함한 집합으로 예측한 값
- f(S) : 피처 i를 빼고 예측한 값
- 차이 = i가 합류했을 때 수익 변화 = i의 한계 기여도
게임 이론 예시로 보면 :
S = {B}, i = A 라면
- f(S U {A}) = f({A, B}) = 180만 원
- f(S) = f({B}) = 80만 원
- 차이 = +100만 원 ⇒ A가 B 팀에 합류했을 때 기여도
2. 덩어리 1

이 수식이 어렵게 생겼지만 결국 하나의 질문에 대한 답이다.
“집합 S가 이미 있고, 다음에 i가 합류하는 순열이 전체 순열 중 몇 % 인가?”
비유 : 줄 세우기
F = {A , B, C} 3명을 일렬로 세우는 경우의 수 = 3! = 6가지이다.
“B가 이미 있고 (S={B}), 그다음에 A가 합류”하는 경우가 몇 가지?
전체 순열 6가지 중에 B-A-C가 해당된다.
6가지 중 1 가지 이므로 확률은 1/6이다.
수식으로 계산하면 아래와 같다.
- |S| = 1 (B 한 명)
- |F| = 3 (전체 3명)
- i = A

- |S|! : S 안의 멤버들이 i 보다 먼저 줄 서는 경우의 수
- (|F| - |S| - 1)! : i 이후 나머지가 줄 서는 경우의 수
- |F|! : 전체 순열 수
(2). 수식 정리

즉, 모든 가능한 합류 상황에서, i의 기여도를 확률로 가중 평균한 값
[3]. 수학적 공리 4가지 (SHAP의 정당성)
{0}. 공리가 왜 필요한가?
먼저 공리란
수학, 논리학 등 이론 체계에서 증명 없이 자명한 진리로 받아들여지는 가장 기초적인 그건가 되는 명제라는 뜻인데
쉽게 말해서
증명 없이 당연하게 받아들이는 전제 조건이다.
HSP이 공정하다는 말을 그냥 믿을 수는 없다.
수학적으로 증명 가능한 조건을 만족해야 공정하다고 할 수 있다.
효율성, 대칭성, 더미, 가산성 이 4가지를 동시에 만족하는 feature attribution 방법은
Shapley Value가 유일하다는 게 수학적으로 증명되어 있다.
{1}. 효율성 (Efficiency)

모든 피처의 SHAP 값을 더하면 정확히 예측값이 된다.
기여도가 누락되거나 중복되지 않는다.
비유하자면 영수증을 생각해 보자.
메뉴 A, B, C를 시켰을 때
각 메뉴 가격의 합 = 총금액이 정확히 맞아야 한다.
1원이라도 모자라거나 넘치면 잘못된 계산서이다.
{2}. 대칭성 (Symmetry)
대칭성의 조건은
피처 i와 j가 모든 연합에서 동일한 기여를 하면 SHAP 값도 같다는 것이다.

실제 기여가 같으면 같은 보상을 받는다.
피처 이름이나 순서 때문에 차별받지 않는다.
비유하자면
두 직원이 매번 똑같은 성과를 냈다면
이름이 "김"이든 "이"든 연봉이 같아야 한다.
이름 순서로 차별하면 불공정하다.
{3}. 더피 (Dummy)
더미의 조건은
피처 i가 어떤 연합에 추가되어도 예측값이 변하지 않으면 SHAP의 값은 0이다.

아무 기여도 안 한 피처는 책임(기여도)도 없다.
비유하자면
팀 프로젝트에서 아무것도 안 한 팀원에게
수익을 나눠줄 이유가 없다.
{4}. 가산성 (additivity)
가산성의 조건은
두 모델을 합친 모델의 SHAP는 각 모델의 SHAP의 합이다.

모델을 합쳐도 SHAP 값이 일관성 있게 유지된다.
비유하자면
두 팀이 각자 번 돈을 합쳐서 공동 수익으로 만들었을 때
각자의 기여도도 단순히 합산하면 된다.
합치는 과정에서 기여도가 뒤바뀌거나 왜곡되지 않는다.
{5}. 정리
| 공리 | 핵심 한 줄 | 위반하면? |
| 효율성 | 모든 SHAP 합 = 예측값 | 기여도 합산이 예측값과 안 맞음 |
| 대칭성 | 기여도가 같으면 SHAP이 같음 | 이름/순서로 차별 발생 |
| 더미 | 기여도 없으면 SHAP = 0 | 무관한 피처가 기여도 가져감 |
| 가산성 | 합친 모델도 일관성 유지 | 앙상블에서 SHAP 신뢰 불가 |
[4]. f(s) 계산 문제 - 피처 일부만 쓴다는 게 뭔가?
예를 들어
모델은 원래 3개 피처를 전부 받아야 작동한다.
- f(소금, 설탕, 후추) = 예측값
그런데 Shapley 계산 중 "소금 피처만 있는 상황"을 만들어야 한다.
그럼 나머지 2개를 어떻게 채우나?
시험 성적 예측으로 비유하자면
선생님이 "공부시간, 수면시간, 컨디션" 3가지로 성적을 예측하는 공식을 만들었다.
그런데 어떤 학생의 수면 시간 정보가 없다.
이때 선생님은 "모르면 일단 반 평균 수면시간을 넣자"라고 한다.
SHAP이 하는 게 정확히 이것이다. 값이 없으면 평균으로 대체한다.
{1}. 없는 피처 = 평균값으로 대체
| 계산해야 하는 상황 | 실제 모델에 넣는 값 |
| 소금크기만 있을 때 | f(소금=실제, 설탕=평균, 후추=평균) |
| 설탕만 있을 때 | f(소금=평균, 설탕=실제, 후추=평균) |
| 아무것도 없을 때 | f(평균, 평균, 평균) |
A 피처 정보가 없다 =피처에 대해 아무것도 모른다.
아무것도 모를 때 가장 무난한 추측 = 평균
정리하면
피처끼리 상관관계가 있으면 "나이가 많을수록 종양도 크다" 평균 대체가 현실에 없는
이상한 조합을 만들어낼 수 있다.
이것이 SHAP의 고질적인 한계 중 하나이다.
[5]. 계산 복잡도 문제와 변형 알고리즘
{1}. 왜 복잡함?
Shapley Value는 모든 피처 조합을 다 계산해야 한다.
피처가 n개면 조합 수는 2^n가지이다.
| 피처 수 | 조합후 |
| 3개 | 8가지 |
| 30개 | 1,073,741,824가지 |
음식 재료 30개가 있고, "각 재료가 맛이 얼마나 기여했나?"를 알고 싶다.
완벽하게 하려면 가능한 모든 재료 조합으로 요리를 만들어서 맛을 비교해야 한다.
30개 재료면 10억 번 요리를 해야 하는데 현실적으로 불가능하다.
그래서 "완벽한 계산"대신 "빠르고 합리적인 근사" 방법들이 등장했다.
{2}. 변형 알고리즘들
(1). Kernel SHAP - 랜덤 샘플링으로 때려잡기
10억 번 요리 대신, 랜덤 하게 1000번만 요리해서 평균을 내는 것,
완벽하진 않지만 충분히 정확하고, 훨씬 빠르다.
- 모든 조합 대신 랜덤하게 일부 조합만 샘플링
- 샘플링한 결과로 선형 회귀를 돌려 기여도 근사
- 모델 종류 무관(블랙박스도 가능)
- 단점 : 여전히 느림 샘플 수가 적으면 부정확
(2). Tree SHAP - 트리 구조를 그대로 이용
요리 레시피가 의사결정 순서도(트리) 형태롤 딱 정해져 있다면,
10억 번 요리 안 해도 순서도만 따라가면 기여도를 정확히 계산할 수 있다.
- 트리 기반 모델(XGBoost, Random Forest 등) 전용
- 트리 구조를 수학적으로 분석해서 정확한 값을 빠르게 계산
- 시간복잡도: 2^n : O(T x L x D^2) (T = 트리 수, L = 리프 수, D = 깊이)
- 현재 가장 많이 쓰는 SHAP 방식
(3). Deep SHAP - 딥러닝 레이어를 역추적
복잡한 공장 생산라인에서 "어떤 공정이 불량에 기여했나?"를 알려고
처음부터 다시 돌리는 게 아니라 역순으로 라인을 거슬러 올라가며 추적하는 것이다.
- 딥러닝 모델 전용
- 역전파 방향으로 기여도를 추적
- 빠르지만 근삿값이기 때문에 완벽하지 않음
{3}. 정리
| 알고리즘 | 비유 | 적용 모델 | 속도 | 정확도 |
| 정확한 Shapley | 10억 번 전부 요리 | 모두 | 느림 | 완벽 |
| Kernel SHAP | 랜덤 1000번 요리 | 모두 | 보통 | 근사 |
| Tree SHAP | 레시피 순서도 분석 | 트리 계열 | 빠름 | 정확 |
| Deep SHAP | 생산라인 역추적 | 딥러닝 | 빠릉 | 근사 |
완벽한 Shapley는 너무 느리니까, 모델 구조에 맞는 지름길을 찾은 게 각 변형 알고리즘이다.
[6]. SHAP 시각화 + 코드
{1}. 코드
# ── 1. 샘플 데이터 생성 ──────────────────────────────
np.random.seed(42)
n = 200
data = pd.DataFrame({
'종양크기': np.random.uniform(0.5, 5.0, n),
'위치': np.random.uniform(0.0, 1.0, n),
'나이': np.random.uniform(20, 80, n),
'혈압': np.random.uniform(60, 140, n),
'MRI강도': np.random.uniform(0.1, 1.0, n),
})
prob = 1 / (1 + np.exp(-(
1.5 * data['종양크기'] +
0.8 * data['MRI강도'] * 5 +
0.3 * (data['나이'] - 50) / 10 -
3.0
)))
y = (prob > 0.5).astype(int)
# ── 2. 모델 학습 ─────────────────────────────────────
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(data, y)
# ── 3. SHAP 계산 ─────────────────────────────────────
explainer = shap.TreeExplainer(model)
shap_values = explainer(data)
sv = shap_values[:, :, 1] # class=1 (악성) 기준{2}. 코드 흐름
(1). 샘플 데이터 생성
- 종양크기, 위치, 나이, 혈압, MRI 신호강도 200개 데이터 생성
- prob 수식으로 악성 확률 계산 : 0.5 넘으면 악성(1), 아니면 양성(0)
※ 종양크기(1.5)와 MRI강도(0.8*5=4.0)가 가중치가 높아서 예측에 가장 큰 영향
(2). 모델 학습
- RandomForest가 위 데이터로 "악성 vs 양성" 분류 학습
- (SHAP이 설명할 블랙박스 모델)
(3). SHAP 계산
- TreeExplainer : RandomForest 전용 SHAP 계산기 생성
- explainer(data) : 전체 200개 데이터에 대해 SHAP값 계산
- sv = shap_values [:, :, 1] : 악성(class=1) 기준 SHAP값만 추출
→ 200명 × 5개 피처 각각의 기여도 행렬이 만들어짐
{3}. 결과
(1). Summary Plot - 전체 피처 중요도 한눈에
30명 학생(데이터) 전원의 과목별(피처별) 기여도를 한 장에 모아놓은 성적표와 같다.
어떤 과목이 전체 합격/불합격에 가장 영향을 많이 줬나?"를 한눈에 파악할 수 있다.
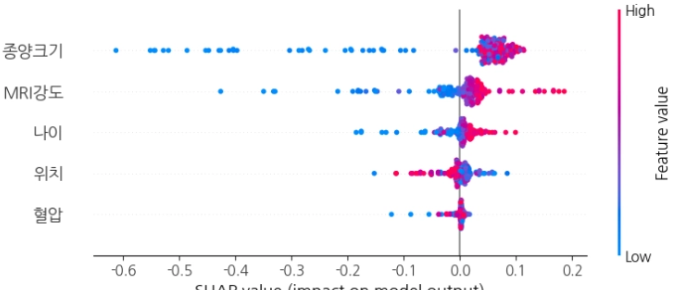
1. 종양 크기
- 빨간 점(값 높음)이 오른쪽(+방향)에 몰려있음
- 파란 점(값 낮음)이 왼쪽(-방향)에 퍼져있음
- 종양이 클수록 악성 확률 올림, 작을수록 내림
2. MRI 강도
- 종양크기와 동일한 패턴
- MRI 신강도가 높을수록 악성 확률 올림
3. 나이
- 점들이 0 근처에 몰려 있음
- 나이는 영향이 있지만 상대적으로 약함 (가중치 0.03으로 설정했기 때문)
4. 위치 / 혈압
- 점들이 전부 0 근처에 집중
- 예측에 거의 영향 없음
데이터를 만들 때 "종양크기, MRI 신호강도가 중요하다"라고 설정했는데,
SHAP이 모델을 분석해서 정확히 그걸 찾아냈다.
모델이 어떤 근거로 판단했는지 역추적하는 게 XAI의 핵심이다.
(2). Force Plot - 줄다리기
아래 그림은 줄다리기 기준값(0.91)에서 시작해서,
빨간 팀(올리는 피처) vs 파란 팀(내리는 피처)이 최종 예측값(0.98)으로 끌어당기는 그림이다.

이 환자의 종양크기와 MRI 신호강도 때문에 악성 확률이 0.91에서 0.98로 올라갔고,
나이가 젊다는 점(26세)이 유일하게 악성 확률을 낮추고 있다.
(3). Waterfall Plot - 가계부
월초 잔액(기준값)에서 시작하여 수입/지출이 한 줄씩 쌓여가며 월말 잔액(최종 예측값)이 되는 과정을 보여주는 가계부이다.
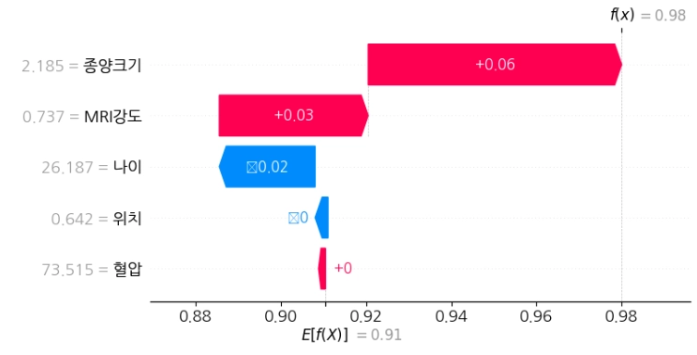
종양크기(+0.06)와 MRI 신호강도(+0.03)가 기준값 0.91을 0.98로 끌어올렸고,
젊은 나이(-0.02)가 유일하게 소폭 낮추고 있다.
(4). Dependence Plot - 종양크기 성장 패턴
특정 피처의 값이 변할 때 SHAP 기여도가 어떻게 바뀌는지,
다른 피처와의 상호작용까지 색깔로 함께 보여주는 그래프다

종양크기 2cm 이하면 악성 확률을 크게 내리고, 2cm 이상이면 일정하게 올린다. 특히 작은 종양일 때 MRI 강도가 낮을수록(파란 점) 양성 판정이 더 강해진다.
SHAP은 같은 결과를 목적에 따라 다양한 방식으로 시각화할 수 있다.
- 전체 경향을 보려면 Summary Plot,
- 1건의 예측을 설명하려면 Force Plot / Waterfall Plot,
- 특정 피처의 패턴을 보려면 Dependence Plot을 사용한다.
[7]. SHAP의 한계
{1}. 피처 간 상관관계 문제
"없는 피처 = 평균으로 대체" 가정 때문에 발생한다.
예를 들면
키와 몸무게는 상관관계가 있는데, 키=140cm, 몸무게=5000kg 같은 현실에 거의 없는 조합으로 계산하는 것이다.
이러면 모델이 학습할 때 이런 조합을 거의 본 적 없기 때문에 예측값 자체가 불안정해지며, SHAP 기여도도 왜곡된다.
{2}. 계산 비용
피처가 많아질수록 조합이 2^n으로 늘어난다. Kernel SHAP으로 근사해도 느리다.
예를 들면
재료가 30개인 요리의 기여도를 측정하려면 아무리 빠른 방법을 써도 오래 걸린다.
{3}. 인과관계 ≠ 기여도
SHAP은 "얼마나 기여했나"는 말해주지만, "왜 기여했나"는 모른다.
예를 들면
성적표는 "수학이 성정에 기여했다"라고 알려주지만, "왜 수학을 잘했나?"는 알려주지 않는다.
{4}. 모델 의존
SHAP은 모델의 예측을 설명하는 것이지, 현실을 설명하는 게 아니다.
모델 자체가 틀리면 SHAP 설명도 틀린다.
예를 들면
잘못된 지도를 아무리 잘 해석해도 결국 길을 잘못 안내하게 된다.
{5}. 전문가가 아닌 사람에게 설명이 어렵다.
SHAP 값 자체가 숫자라서 환자/보호자 같은 일반인에게 직접 설명하기 어렵다.
의사가 "이 수치가 +0.06 기여했습니다"라고 해도 환자는 이해하지 못한다.
[8]. 결론
SHAP은 모델이 뭘 봤는지는 잘 설명하지만,
그게 현실에서 왜 그런지 까지는 말해주지 못한다.
출처 :
https://velog.io/@sjinu/개념정리SHAPShapley-Additive-exPlanations
'AI > AI' 카테고리의 다른 글
| Attribution (0) | 2026.05.03 |
|---|---|
| XAI 기법 - LIME (1) | 2026.05.02 |
| Attention Mechanism (0) | 2026.05.02 |
| Saliency Map (0) | 2026.04.30 |
| Activation Function (활성화 함수) (0) | 2026.04.29 |