LLM은 본질적으로 아는 것처럼 보이도록 그럴듯한 문장을 생성하는 모델이다. 이로 인해 정확한 정보가 요구되는 질문(법, 논문, 의학, 최신 정보 등)을 받았을 때, 명확한 근거가 없으면 추측에 기반한 답변을 생성하는 경우가 발생할 수 있다. 이러한 현상은 이전 글에서도 언급한 AI 환각(hallucination)에 해당된다.
1. RAG
논문에서 언급되는 RAG(Retrieval-Augmented Generation)는 이러한 문제를 완화하기 위한 기법으로, 대규모 언어 모델이 답변을 생성할 때 외부 지식 베이스에서 관련 정보를 검색한 후, 이를 근거로 답변을 생성하는 방식이다.
즉, RAG는 답변을 생성하기에 앞서 관련 문서를 먼저 검색하고, 해당 문서를 바탕으로 응답을 구성하는 구조를 가진다.
이러한 방식은 LLM이 기존처럼 그럴듯한 문장을 생성하는 데 그치지 않고, 실제 근거가 되는 정보를 기반으로 답변하도록 유도함으로써 응답의 신뢰성을 크게 향상시킨다.
RAG를 적용할 경우, 환각이 감소하는 이유는, LLM이 상상이나 추론만으로 답변을 생성하는 것이 아니라 실제 텍스트 자료인 문서, 논문, 블로그 등을 참고하기 때문에 존재하지 않는 정보를 임의로 생성하기 어려워진다.
결과적으로 오답이 발생할 확률이 크게 감소한다.
이러한 환각 감소 효과는 다양한 측면에서 의미를 가지며, 그중에서도 AI 보안 및 AI Safety 관점에서 특히 중요한 의미를 가진다.
LLM이 생성하는 응답은 사용자에게 사실로 받아들여질 가능성이 높기 때문에, 잘못된 정보가 제공될 경우 실제 의사결정 오류나 피해로 이어질 수 있다.
따라서 환각 문제는 정확도의 문제가 아니라, 신뢰성과 안전성의 문제로 다루어져야 한다.
이러한 관점에서 RAG는 LLM의 위험성을 구조적으로 완화하는 핵심 기법으로 평가된다.
(1). AI 보안 / AI Safety 관점에서 RAG의 의미
RAG는 LLM이 추론이나 상상에 의존해 답변을 생성하는 방식에서 벗어나, 외부 자료를 근거로 응답하도록 유도하는 구조적 안전장치이다.
LLM은 자신감 있게 말은 잘하는데 틀려도 틀린 줄 모른다. 근데 이게 보안적으로 매우 위험하다. 이유는 아래와 같다.
- 법률 조언을 틀리게 하면?
- 의료 정보를 지어내면?
- 잘못된 보안 설정을 하게 안내하면?
⇒ 이러한 이유들 때문에 피해를 볼 수 있다.
그래서 RAG는 LLM에게 관련된 문서들을 근거로만 말하라고 명령를 한다.
LLM이 RAG를 사용하면
환각이 줄어들어 잘못된 정보 전파가 감소한다.
근거 기반 응답으로 스스로 감사가 가능해진다.
모델 내부 지식 의존이 낮아 지면서 LLM을 통제할 수 있게 된다.
즉, LLM의 자유도를 줄여서 안전성을 높이는 구조가 RAG이다.
(2). 안전한 설계
https://brunch.co.kr/@ressac-n/62
10화 Safety by Design, AI 안전 패러다임
AI 개발에 안전모를 씌운다면 | 혁신적인 AI 기술이 우리 삶 모든 영역에 빠르게 스며들고 있는 가운데 AI의 악용가능성, AI의 기술적 한계 때문에 각국 정부(EU , 미국, 한국)는 어떤 노력을 기울이
brunch.co.kr
의 글을 보면 AI 서비스, rAG 시스템을 구축할 때 개발 후순위로 밀리기 쉬운 안전과 윤리를 어떻게 시스템 구조 자체에 녹여낼 것인가를 다루고 있다.
1. Safety-by-Design
Safety by Design(SbD, 설계 기반 안전)은 제품, 서비스, 시스템 개발의 초기 기획 단계부터 안전을 핵심 요소로 고려하여, 개발 전 과정에 걸쳐 안전을 내재화하는 접근 방식이다.
블로그에서 말하는 핵심은 AI의 위험성(편향성, 환각, 개인정보 유출 등)을 서비스가 완성된 후, 필터링하는 것이 아니라, 기획과 설계 단계부터 기술적, 정책적 장치를 심어두는 것이다.
RAG 시스템은 외부 지식을 가져오기 때문에 통제력이 높지만, 그만큼 연결 통로마다 위험 요소가 존재한다.
이를 설계 단계에서 해결하는 것이 핵심이다.
RAG는 작동 단계가 세 단계로 구성되어 있따. Input, Retrieval, Output 이 세 단계에서 Safety-by-Design을 적용하면 아래와 같다.
1단계. 입력 단계 : Prompt Safety (사용자로부터의 보호)
- 사용자의 질문이 데이터베이스를 비정상적으로 탈취하려 하거나, 시스템 가이드라인을 벗어나는 질문인지 판단하는 가드레일 모델을 검색 전 단계에 배치한다.
2단계. 검색 및 *컨텍스트 단계 : Data Integrity (데이터로부터의 보호)
- 사용자마다 접근 가능한 문서 범위를 메타데이터로 관리하여, AI가 답변을 생성할 떄 본인 권한 밖의 문서는 아예 읽지 못하도록 설계한다.
- 벡터 DB에 저장되는 문서 중 편향되거나 혐오 표현이 포함된 내용은 사전에 필터링하여 검색 대상에서 제외한다.
? 컨텍스트 : 텍스트나 말의 표면적 의미를 넘어선 맥락, 문맥, 주변 상황, 환경, 숨겨진 의도 등을 포괄하는 개념
3단계. 생성 및 검증 단계 : Hallucination * Ethics (출력으로부터의 보호)
- 생성된 답변이 참조된 문서에 실제로 존재하는지 교차 검증하는 로직을 넣는다.
- 모르는 내용이거나 답변하기 부적절한 경우, 억지로 답하지 않고 "답변할 수 없습니다" 라고 안전하게 거절하도록 프롬프트와 로직을 설계한다.
블로그에서는 AI 서비스의 경쟁력은 이제 단순히 성능이 아니라 안전과 신뢰에서 나온다고 말한다. RAG 시스템을 공부할 때 기술적 매커니즘(임베딩, 벡터 검색 등)만 보는 것을 넘어, Safety-by-Design의 질문을 던져보는 것도 좋다.
- 내가 참조하는 문서들은 정말 안전하고 최신 정보인가?
- 답변 생성 과정에서 개인정보가 노출될 구멍은 없는가?
- AI가 틀린 말을 했을 때, 사용자가 이를 인지할 수 있는가?
Safety-by-disign은 RAG를 단순히 똑똑한 AI를 만드는 기술이 아니라 현업에서 실제로 쓸 수 있는 책임감 있는 도구로 만드는 설계 원칙이라고 이해하면 된다.
(3). RAG를 써도 환각이 완전히 사라지지 않는 이유
RAG는 LLM의 환각을 크게 완화할 수 있는 효과적인 기법이지만, 환각을 완전히 제거하는 해결책은 아니다.
이는 RAG가 외부 문서를 참고하도록 구조를 바꾸는 방식이지, LLM의 생성 매커니즘 자체를 결정론적으로 만드는 기술은 아니기 때문이다.
1. 검색된 문서 자체가 틀림
RAG는 아래처럼 동작한다.
- 문서 검색
- 해당 문서를 보고 답변 생성
근데 만약에
- 오래된 문서이거나
- 블로그 글이 틀렸거나
- 애매하게 쓰여 있다면?
근거가 있어도 틀린 답이 나올 수가 있다.
RAG는 진짜 정보를 보장하지 않고, 찾아온 정보를 사용할 뿐이다.
2. 검색은 했지만, 문서를 잘못 해석할 수 있음
LLM은 언어 모델이다.
- 문서 일부만 보고 과도한 일반화
- 조건을 빼먹고 단정적으로 말함
- 여러 문서를 섞어서 이상한 결론 도출
⇒ 이것은 추론 오류 기반 환각이 될 수 있다.
3. 질문 자체가 애매하면 환각이 생김
- 이게 안전한가?
- 보통은 어떻게 하나?
⇒ 기준이 없고, 정답도 하나가 아니다.
그래서 LLM은 문서를 참고하면서도 빈 부분을 추측으로 채움
4. LLM은 모르면 모른다가 기본값이 아니다.
LLM은 기본적으로 다음에 올 단어(token)를 가장 그럴듯하게 예측하도록 학습된 모델이다.
즉, 학습 과정에서 모델은 "이 질문에 대해 가장 많이 등장했던 답변 패턴은 무엇인가?"를 맞힌느 방향으로 보상을 받는다.
이 과정에서
"모르겠습니다', "답변할 수 없습니다"와 같은 응답은 학습 데이터에서 상대적으로 빈도가 낮고
반면, 질문에 대해 그럴듯한 설명을 이어가는 답변은 훨씬 자주 등장하며, 언어적으로도 높은 확률을 가진다.
그 결과, 모델 입장에서는
아무 말도 하지 않는 것보다, 그럴듯한 답변을 생성하는 쪽이 손실을 줄이는 방향이 된다.
즉, LLM은 정답을 아는지 여부를 판단하도록 학습된 것이 아니라, 주어진 맥락에서 가장 자연스럽게 이어질 문장을 생성하도록 학습되었기 때문에, 불확실한 상황에서도 답변을 시도하는 성향을 갖게 된 것이다.
근데 요즘 LLM은 "답변할 수 없다"고 말하기도 한다
사이버 공격 방법, 성적, 폭력적, 불법 행위와 같은 질문에 대해 의도적으로 "답변할 수 없다" 고 응답하는 경우가 많다.
이는 LLM이 사후적으로 안전 제약이 추가되었기 때문이다.
위에서도 말했듯이 LLM의 기본 성향은 그럴듯하게 답하는 것이다. 근데
- RLHF(Reinforcement Learning from Human Feedback)
- 정책 기반 필터링
- 프롬프트 가드레일
위와 같은 외부 제약이 추가되면서,
이 유형의 질문에 대해서는 그럴듯한 답변을 생성하는 것보다 답변을 거부하는 것이 더 높은 보상을 받도록 행동이 강제로 교정된 것이다.
그래서 RAG와도 연결된다.
RAG가 있어도 환각이 완전히 사라지지 않는 이유는
- RAG는 근거를 제공할 뿐
- LLM의 기본 생성 성향까지 바꾸지는 않기 때문이다
따라서 실제 안전한 시스템을 만들기 위해서는
- RAG (근거 제공)
- Guardrail (위험 질문 차단)
- Output 검증 (생성 결과 확인)
이 함께 설계되어야 한다.
2. GraphRAG
기존 RAG는 질문 → 관련 문서 검색 → 해당 문서만 보고 답변 생성 이렇게 동작한다.
근데 문제는 문서가 많고, 도메인이 복잡할수록 문서 사이의 관계가 잘린다는 것이다.
즉, 각각의 문서는 잘 찾아오지만 1번 문서와 2번 문서가 어떻게 연결되는지에 대한 맥락은 쉽게 사라진다.
그래서 이러한 한계를 보완하기 위해 GraphRAG가 제안되었다.
이를 통해
- LLM이 단편 문서가 아닌
- 맥락과 관계까지 함께 이해하도록 하려는 시도였다.
특히, 대규모 비정형 데이터나 논문, 뉴스, 보고서처럼 얽힌 정보에서 컨텍스트 손실을 줄일 수 있을 거라 기대한 것이다.
(1). 근데 왜 생각보다 별로라는 말이 나옴?
최근 연구들이 말하는 핵심은 GraphRAG가 이론적으로 좋아 보이지만 실제 성능은 오히려 일반 RAG보다 떨어지는 경우가 많다고 한다.
그 이유는 아래와 같다.
1. 그래프가 너무 복잡해짐
- 노드가 많아지고
- 관계도 많아져서
- LLM이 한 번에 이해해야 할 정보가 폭증함
⇒ 오히려 중요한 정보가 묻힐 수도 있음
2. 그래프 품질이 성능을 좌우함
- GraphRAG는 관계 정의가 핵심인데
- 관계가 부정확하거나 애매하거나, 자동 추출로 대충 만들어지면 잘못된 맥락을 더 강하게 주입하게 됨
3. 비용 대비 효율이 낮음
- 그래프 구축 비용이 비쌈
- 유지보수 어려움
- 추론 과정도 복잡함
그래서 성능은 일반 RAG랑 비슷한데, 효율이 떨어지면 굳이 써야 되나? 라는 의문이 생긴 것이다.
GraphRAG는 만능 해결책이 아니라 특정 상황에서만 의미 있는 도구일 수 있다 라는 방향으로 논의가 바뀌고 있다.
(2). GraphRAG 시험장
1. *벤치마크 문제?
RAG 벤치마크들은
- 문서 하나에서 답 찾기
- 단순한 키워드 검색
- 문서 간 관계가 거의 없는 구조
⇒ 이러한 문제를 갖고 있음
그래서 그래프 구조가 필요하지 않은 문제에서도 GraphRAG를 평가하게 되는 상황이 발생하며, 이 경우 GraphRAG의 강점이 제대로 드러나기 어렵다. .
? 벤치마크 : 컴퓨터공학에서 컴퓨터, 스마트폰 등 전자기기의 연산성능을 시험하여 수치화하는 것
논문에서는 GraphRAG가 진짜 잘하는 상황을 제대로 평가할 수 있는 시험장이 필요하다고 판단하고 GraphRAG-Bench를 만들었다.
2. GraphRAG-Bench는 다른가?
- 문서들이 서로 얽혀 있음
- 관계를 이해하지 않으면 답을 못함
- 단순 검색으로는 해결 안됨
즉, 그래프 구조를 써야만 유리한 문제들로 구성된 벤치마크 데이터셋을 제안한 것이다.
3. GraphRAG-Bench Framework
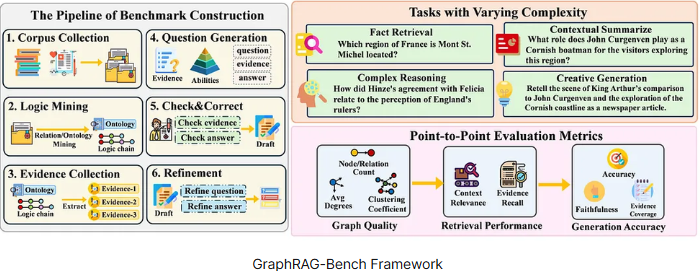
논문에서 제시된 그림은 GraphRAG-Bench를 구성하는 전체 프레임워크를 보여주며, 크게 벤치마크 구축을 위한 6단계 파이프라인과 그 이후의 태스크 설계 및 평가 방식으로 구성되어 있다.
1 단계 : 실제 데이터 수집
의료 문서, 논문 같은 현실적이고 복잡한 비정형 텍스트를 사용
일부러
- 모호한 표현
- 도메인별 계층 구조를 섞어서 검색 + 추론이 모두 어려운 상황을 만듦
⇒ 실제 현업에서 GraphRAG가 쓰일 만한 데이터를 만드는 단계이다.
2~3 단계 : 텍스트를 개념 그래프로 변환
LLM을 사용해서
- 텍스트 속 개념, 인물, 사건을 뽑고
- 이들 사이의 관계(원인, 포함, 대비 등)를 명시적으로 연결
그냥 문장이 아닌, 이 개념이 저 개념과 어떻게 연결되는지를 구조화한다.
⇒ 이 과정에서 추론 난이도도 함께 정량화가 된다.
4 단계 : 질문 생성
- 방금 만든 증거 구조(그래프)를 보고
- 그 구조를 실제로 이해해야만 풀 수 있는 질문을 생성
⇒ 그래프를 안 보면 못 푸는 질문
예를 들면
- A 논문은 B 이론을 비판함
- B 이론은 C 가설을 기반함
- C 가설은 D 실험 결과에서 도출
- D 실험은 2025년에 수행
이렇게 정보들이 흩어져 있는데 GraphRAG는 아래처럼 만든다.
A 논문 ──비판──▶ B 이론 ──기반──▶ C 가설 ──도출──▶ D 실험 ──연도──▶ 2025
음.. 그러니까 그래프를 봐야만 풀 수 있는 질문 예시를 들면
1. 연결 추론형
질문 : A 논문이 간접적으로 의존하고 있는 실험은 언제 수행되었는가?
같은 질문세어 왜 그래프가 필요하냐면
A 논문 → B 이론 → C 가설 → D 실험
이 연결 사슬을 따라가야만 답이 나옴
⇒ 단순 A 논문 + 실험으로 검색해도 안나온다.
2. 관계 방향 이해형
질문 : A 논문이 비판하는 이론의 근간이 되는 가설은 무엇인가?
- "비판" 이라는 관계
- "기반이 된다"는 관계
를 방향까지 정확히 이해해야 답변이 가능하다
이 상황에서 그래프 구조가 없으면 그냥 단어 매칭으로 헷갈리기 쉽다.
3. 다중 문서 통합형
질문 : 2025년 실험 결과를 기반으로 한 이론을 비판한 문서는 무엇인가?
해당 질문은
- 연도 정보
- 실험 → 가설 → 이론 → 논문을 거꾸로 추론해야 한다.
⇒ 이건 그래프 traversal 문제로 그래프 탐색 없이 거의 불가능에 가깝다.
Drug A ──targets──▶ Protein X ──involved in──▶ Disease Y Protein X ──activated by──▶ Pathway Z
위 그래프를 통해서 "Disease Y에 영향을 주는 경로(Pathway)는 무엇인가" 라는 질문을 한다면
⇒ 연결고리를 따라가서 찾아야한다.
5 단계 : 검증과 수정
질문 증거, 정답이
- 틀리지 않았는지
- 서로 잘 맞는지
다시 확인하고 수정
⇒ 벤치마크 신뢰성 확보
6 단계 : 배경 지식 통합
추가 배경 정보를 섞어서 질문을 더 풍부하고 어렵게 다듬는다.
⇒ 단순 QA가 아닌, 사고가 필요한 문제를 완성
(1). 난이도별 태스크 구성

쉬운 문제부터 어려운 문제까지 4단계로 구성
1. 사실 검색
- 단순 정보 찾기
- A는 어디에 위치하는가?
⇒ 일반 RAG도 잘하는 수준의 문제
2. 복잡한 추론
- 여러 정보 조합
- 관계를 따라가야 답이 나옴
⇒ GraphRAG가 유리할 수 있는 구간
3. 컨텍스트 요약
- 여러 문서를 종합해서 요약
- 맥락 이해가 핵심
⇒ 문서 간 연결 이해 필요
4. 창의적 생성
- 비교, 재해석, 새로운 글 생성
- 단순 검색으로는 불가능
⇒ 그래프 기반 맥락 이해 + 생성 능력 모두 요구
(2). 평가

1. 그래프 품질
- 노드 수
- 관계 수
- 연결 구조가 잘 만들어졌는지
⇒ 그래프 자체가 괜찮은가?
2. 검색 성능
- 질문에 맞는 문서를 잘 가져왔는가
- 맥락적으로 중요한 증거를 찾았는가
⇒ 그래프 + 검색이 제대로 작동했는가?
3. 생성 정확도
- 답변이 맞는가?
- 근거에 충실한가?
- 지어내지 않았는가?
⇒ 최종 답변이 믿을 만한가?
그래프를 안 보면 못 푸는 질문이 GraphRAG-Bench 질문 생성의 핵심이다.
4. LLM에 GraphRAG-Bench 데이터셋 테스트
논문에서는 GraphRAG-Bench 데이터셋을 활용하여 GPT-4o-mini와 Qwen2.5-14B 기반에서 다양한 GraphRAG 모델과 기본 RAG의 성능을 비교, 분석하였따.
(1). 생성 정확도 관점
"답을 어마나 잘 만들어냈는가?"
- 쉬운 질문
쉬운 문제에서는 RAG와 GraphRAG는 다를게 없다. 사실상 GraphRAG가 필요 없다.
- 그래프가 필요 없음
- GraphRAG는 오히려 쓸데없는 정보까지 가져옴
- 답변이 흐려질 수 있음
⇒ 쉬운 문제에 GraphRAG는 과한 도구가 된다.
- 어려운 질문 (복잡한 추론, 요약, 창의적 생성)
GraphRAG가 더 잘함
- 여러 개념 간 관계를 따라가야 함
- 문서 여러 개를 연결해야 함
- 맥락을 종합해야 하기 때문
이건 그래프 구조의 본래 강점이 들어나는 구간
- 창의적 생성에서의 특징
- RAPTOR(GraphRAG 계열)가 소설(Novel) 데이터셋에서 최고 성능
- GraphRAG는 사실 오류가 적고 정밀한 답을 잘 만듦
하지만
- 정보가 조각으로 나뉨
- 넓고 포괄적인 답변은 약함
1. GraphRAG = 정확하지만 좁음
- 그래프를 따라 관련된 정보만 정확히 골라서
- 근거 중심, 관계 중심으로 답변함
특징 :
사실 오류 적음
질문에 직접 필요한 정보 위주
논리적으로 단단함
단점 :
주변 맥락, 여담, 배경 설명은 적음
답변이 다소 딱딱하고 범위가 제한적
즉, 시험 답안용 답변 → 필요한 말만 정확히 씀
2. RAG = 덜 정확하지만 넓음
- 관련 문서를 폭넓게 가져옴
- 전체 맥락을 감싸는 답변을 만듦
특징 :
- 배경 설명 풍부
- 이야기처럼 자연스러움
- 전체적인 그림을 보여줌
단점 :
- 가끔 부정확한 내용이 섞임
- 질문 핵심에서 살짝 벗어날 수 있음
(2). 검색 성능 관점
"필요한 정보를 잘 찾는가?"
- 쉬운 질문
기본 RAG가 더 깔끔
- 컨텍스트 재현율이 매우 높음(83% 이상)
- GrpahRAG는 필요 없는 관련 정보까지 같이 가져오는 경향
⇒ 그래프가 방해됨
- 어려운 질문
GraphRAG가 압도적으로 유리
HippoRAG / HippoRAG2가
- 증거 재현율
- 컨텍스트 관련성
모두 높게 나옴
⇒ 그래프는 흩어진 정보를 연결하는 데 특화되어 있기 때문에 특히, 의료 데이터셋에서 GraphRAG의 강점이 더 뚜렷하게 나왔다.
- 창의적 생성에서의 특징
GraphRAG
- 더 많은 관련 정보를 가져옴
- 대신 중복이 생길 수 있음
RAG
- 정보는 적지만 더 간결
넓게 보느냐, 깔끔하게 보느냐의 차이
(3). 그래프 복잡도 관점
"그래프가 얼마나 짤 만들어졌나?"
GraphRAG마다 그래프 구조가 완전히 다름
특히 HippoRAG2에서
- 노드도 많고
- 엣지도 많음
- 훨씬 촘촘한 그래프 생성
그 결과로 정보 연결성이 좋아지고, 검색과 생성 성능도 좋아졌다.
⇒ 그래프 품질이 곧 성능이다.
(4). 효율성(토큰 비용) 관점
GraphRAG의 가장 큰 단점이다.
1. 프롬프트 길이
기본 RAG
- 비교적 짧음
GraphRAG
- LightRAG : ~10,000토큰
- Global-GraphRAG : 최대 40,000토큰
⇒ 엄청 무거움
즉 문제 난이도가 올라갈수록
- 그래프가 커짐
- 검색 결과가 많아짐
- 프롬프트 폭증
이 되는데 여기서의 문제는 토큰이 많아질수록
- 중복 정보 증가
- 오히려 컨텍스트 집준도가 하락 될 수 있다.
⇒ 구조화가 높아지면 비용도 높아지는데 그러면 효율성이 떨어진다.
다시 한 번 정리하면
- 쉬운 질문은 기본 RAG가 더 낫다
- 복잡한 추론, 요약, 창의적 생성은 GraphRAG가 강하다
- 그래프 품질이 성능을 좌우한다.
- GraphRAG는 토큰 비용이 매우 크다
- 모든 문제에 쓰면 비효율적이다.
다시 정리해보자
5. 그래서 GraphRAG-Bench가 중요?
GraphRAG는 아래와 같은 의문이 있었다
- GraphRAG가 복잡한 추론에 좋다는데 진짜?
- RAG보다 좋은 경우는 언제?
- 모델하다 성능 차이가 나는 이유는?
문제는 이걸 공정하고 체계적으로 평가할 방법이 없없다는 것이다.
GraphRAG-Bench는
- GraphRAG 전용으로 그래프가 필요한 문제만 골라서 단계별로 성능을 분석할 수 있게 만든 벤치마크이다.
- 그래서 GraphRAG의 장점과 한계를 처음으로 명확하게 드러내줌
(1) GraphRAG vs RAG 뭐가 다른데
사실 검색 같은 쉬운 질문에서는
GraphRAG :
- 불필요한 정보까지 가져옴
- 프롬프트를 어지럽힘
- 성능이 떨어지는 경우가 많음
⇒ 이럴 땐 기본 RAG가 나음
복잡한 작업에서는
- 멀티홉 추론
- 여러 문서를 연결해야 하는 문제
- 깊은 맥락을 이해해야 하는 작업
⇒ GraphRAG가 확실이 강함
왜?
그래프 구조가 흩어진 정보를 연결하고, 관계를 따라 추론하는 데 특화되어 있기 때문에
(2). 모든 GraphRAG가 똑같지는 않다
GraphRAG 모델마다
- 그래프 밀도
- 그래프 품질
- 설계 목적
전부 다르다
그래서
- 어떤 모델은 검색을 잘하고
- 어떤 모델은 생성을 잘하고
- 어떤 모델은 토큰을 많이 쓴다.
⇒ 그래프를 어떻게 만드느냐가 성능을 크게 좌우하게 된다.
(3). 대가도 있어? (토큰 비용)
그래프 기반 접근은
- 정보 정리
- 추론 능력
이 두 개를 확실히 높여준다.
근데
- 프롬프트가 길어지고
- 토큰 비용이 커짐
결국 남는 질문은
⇒ 성능을 얼마나 얻고, 비용은 어디까지 감당할 것인가? 이다. 즉, 성능과 효율 사이의 균형 문제이다.
(4) 그래서 GraphRAG-Bench의 진짜 기여는
GraphRAG-Bench는 단순히 점수 매기는 도구가 아니라
- 언제 써야 하는지
- 어떤 GraphRAG가 어떤 작업에 맞는지
- 어떻게 단점을 줄이고, 활용도를 높일지
⇒ 실제로 현업에서 쓰기 위한 가이드라인을 제공한다.
참고 :
https://www.graphusergroup.com/25-november-3week-graphomakase/
25년 11월 3주차 그래프 오마카세
When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented GenerationGraph retrieval-augmented generation (GraphRAG) has emerged as a powerf
www.graphusergroup.com
https://arxiv.org/abs/2506.05690?ref=graphusergroup.com
When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
Graph retrieval-augmented generation (GraphRAG) has emerged as a powerful paradigm for enhancing large language models (LLMs) with external knowledge. It leverages graphs to model the hierarchical structure between specific concepts, enabling more coherent
arxiv.org
[LLM][RAG] RAG(Retrieval-Augmented Generation) 소개 및 설명
[LLM][RAG] RAG(Retrieval-Augmented Generation) 소개 및 설명1. RAG의 정의 및 중요성RAG의 정의RAG는 Retrieval-Augmented Generation의 약자로, 정보 검색과 생성 모델을 결합한 자연어 처리(NLP) 기술을 의미합니다.
dwin.tistory.com
'AI > 그래프 오마카세' 카테고리의 다른 글
| 25.11.4 NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes (1) | 2025.12.26 |
|---|---|
| GraphFrame, AI, 가짜뉴스 (1) | 2025.12.17 |
| 25.11.2 GraphFrame (1) | 2025.12.17 |
| 25.11 1주차 Verifying Chain-of-Thought Reasoning via Its Computational Graph (1) | 2025.11.30 |